在農(nóng)歷新年之際,科技界的焦點(diǎn)并未因節(jié)日氛圍而黯淡,反而因一家杭州“小公司”DeepSeek的崛起而更加熾熱。DeepSeek以其創(chuàng)新的AI技術(shù),為整個行業(yè)帶來了新的活力和思考。
自DeepSeek-V3模型去年年底發(fā)布以來,其性能便備受矚目。該模型在多項(xiàng)評測中超越了Qwen2.5-72B和Llama-3.1-405B等開源模型,與閉源模型GPT-4o和Claude-3.5-Sonnet不相上下。這一成就迅速吸引了業(yè)內(nèi)人士的廣泛關(guān)注,但DeepSeek的真正“出圈”還要等到其手機(jī)應(yīng)用上線前夕。
1月20日,DeepSeek再次發(fā)力,推出了推理模型DeepSeek-R1。該模型在性能上實(shí)現(xiàn)了對OpenAI-o1正式版的對標(biāo),并且DeepSeek大方地公開了DeepSeek-R1的訓(xùn)練技術(shù),同時開源了模型權(quán)重。對普通用戶而言,DeepSeek-R1更是直接在官網(wǎng)上免費(fèi)開放使用,這一舉措無疑為AI技術(shù)的普及和應(yīng)用注入了新的動力。
DeepSeek-R1不僅性能卓越,而且使用靈活。它支持聯(lián)網(wǎng)搜索信息,增加了使用的便捷性。同時,作為一款采用CoT思維鏈技術(shù)的推理模型,DeepSeek-R1能夠向用戶展示其思考過程,讓用戶直觀感受到大模型技術(shù)的實(shí)力。這一特點(diǎn)在海內(nèi)外全網(wǎng)引發(fā)了熱烈討論,DeepSeek也因此承受了巨大的訪問壓力和惡意攻擊。

DeepSeek的成功并非偶然。其兩大核心技術(shù)——MoE混合專家模型和RL強(qiáng)化學(xué)習(xí),為其帶來了顯著的成本優(yōu)勢和性能提升。MoE架構(gòu)通過將一個復(fù)雜問題分解成多個更小、更易于管理的子問題,并由不同的專家網(wǎng)絡(luò)分別處理,從而大大降低了推理成本。而RL強(qiáng)化學(xué)習(xí)則完全依賴環(huán)境反饋來優(yōu)化模型行為,使模型在訓(xùn)練中自主發(fā)展出自我驗(yàn)證、反思推理等復(fù)雜行為,達(dá)到ChatGPT o1級別的能力。

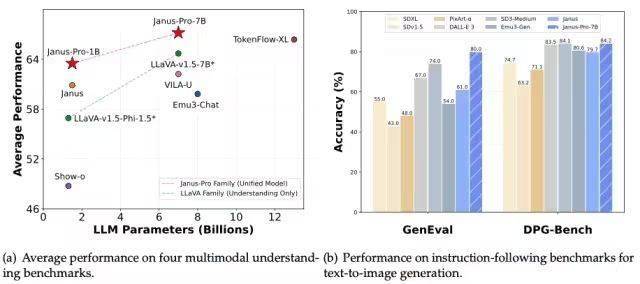
盡管DeepSeek-V3和DeepSeek-R1已經(jīng)足夠強(qiáng)大,但他們?nèi)匀恢皇恰按笳Z言模型”,不具備多模態(tài)能力。然而,DeepSeek并未止步于此。1月28日凌晨,DeepSeek開源了全新的視覺多模態(tài)模型Janus-Pro-7B。該模型通過將視覺編碼過程拆分為多個獨(dú)立的路徑,解決了以往框架中的局限性,同時仍采用單一的統(tǒng)一變換器架構(gòu)進(jìn)行處理。這一創(chuàng)新使Janus-Pro在Geneval和DPG-Bench基準(zhǔn)測試中擊敗了Stable Diffusion和OpenAI的DALL-E 3。

DeepSeek的崛起引起了AI大模型領(lǐng)域其他公司的關(guān)注。在DeepSeek-R1發(fā)布后不久,阿里通義團(tuán)隊(duì)便推出了Qwen2.5-Max模型。該模型使用超過20萬億token的預(yù)訓(xùn)練數(shù)據(jù)及精心設(shè)計(jì)的后訓(xùn)練方案進(jìn)行訓(xùn)練,性能表現(xiàn)與業(yè)界領(lǐng)先的模型相當(dāng)。Qwen2.5-Max的發(fā)布不僅展示了阿里在AI技術(shù)上的實(shí)力,也反映了DeepSeek對行業(yè)的影響力和推動力。
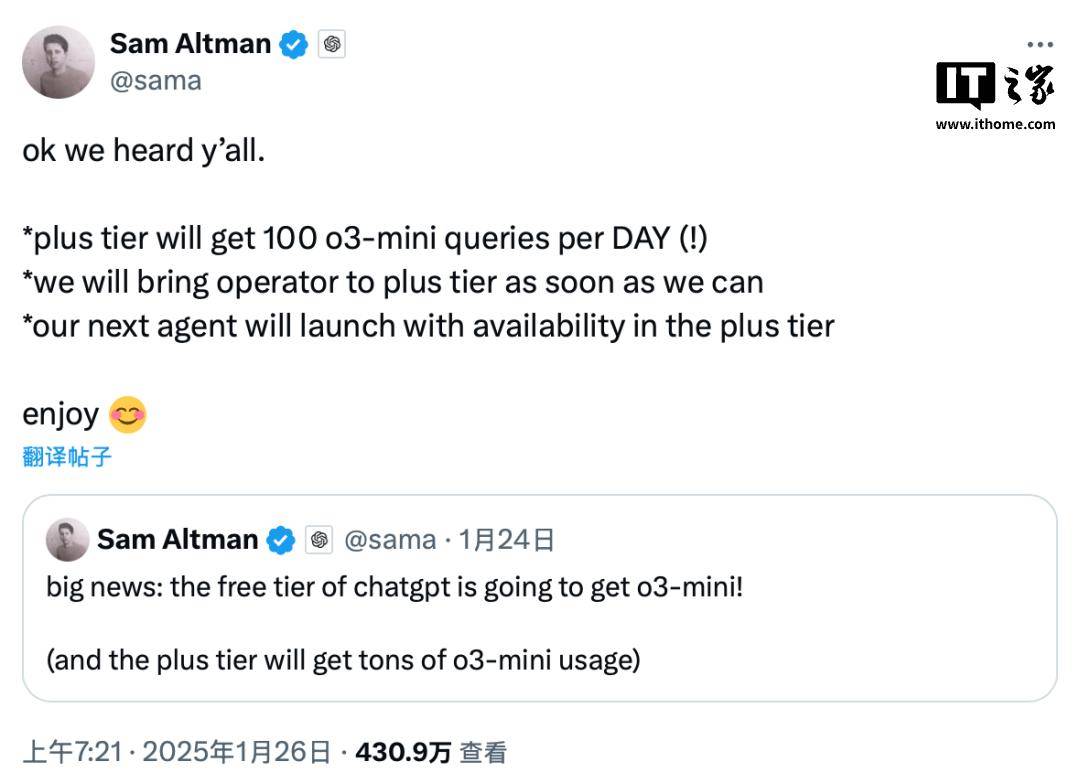
面對DeepSeek等競爭對手的壓力,OpenAI的CEO阿爾特曼也表示將采取一系列措施來優(yōu)化成本和提升用戶體驗(yàn)。他透露,未來的ChatGPT o3-mini模型將開放給免費(fèi)用戶使用,Plus會員則每天有100條請求的額度。同時,新的ChatGPT Operator功能也將盡快向Plus會員開放。