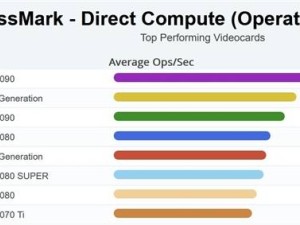
摩爾線程科研團隊近期公布了一項創新研究成果,名為《Round Attention:利用輪次塊稀疏性革新多輪對話優化路徑》。這一突破性進展使得推理引擎的端到端延遲顯著低于當前主流的Flash Attention,同時在鍵值緩存(kv-cache)顯存占用上實現了最高82%的節省。
隨著AI大型語言模型的快速發展,語言模型服務在日常問題解決任務中的應用日益廣泛。然而,長時間的用戶交互帶來了兩大挑戰:一是上下文長度的急劇增加導致自注意力機制的計算開銷劇增,因其復雜度與長度的平方成正比;二是鍵值緩存技術雖然在一定程度上緩解了冗余計算問題,但隨之而來的GPU內存需求激增,限制了推理批處理的規模,降低了GPU的利用率。
為了應對這些挑戰,摩爾線程提出了Round Attention機制。該機制的核心在于以輪次為單位分析Attention規律,專為多輪對話場景設計。通過對輪次粒度的Attention分布進行深入研究,摩爾線程發現了兩個重要規律,這些規律為優化提供了理論基礎。
基于這些發現,摩爾線程進一步設計了Round Attention推理流水線。這一流水線將稀疏性從傳統的Token級提升到了塊級,通過選取最相關的塊參與Attention計算,顯著減少了計算耗時。同時,將不相關的塊卸載到CPU內存,從而有效節省了顯存占用。這一策略在保持推理精度的前提下,顯著提升了推理效率并降低了資源消耗。
摩爾線程指出,輪次塊稀疏性具有三大顯著優勢:首先,以輪次為自然邊界的劃分保證了語義的完整性;其次,在分水嶺層實現了注意力的穩定性;最后,在端到端層面實現了存儲與傳輸的優化。這些優勢共同促成了Round Attention的高效表現。
實驗結果顯示,與主流的Flash Attention推理引擎相比,Round Attention在端到端延遲方面表現出色,同時在kv-cache顯存占用上節省了55%至82%。在主觀評測和客觀評測的兩個數據集上,模型推理準確率基本保持不變,驗證了Round Attention的有效性和實用性。