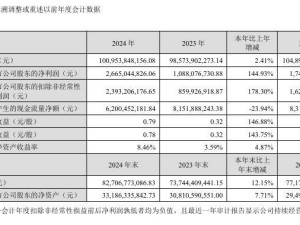
阿里云在最新一輪的技術創新中,推出了通義千問Qwen模型家族的新成員——Qwen2.5-Omni。這款旗艦級端到端多模態模型不僅向公眾展示了其強大的技術實力,還通過開源的方式,在Hugging Face、ModelScope、DashScope和GitHub等平臺上供開發者使用。
Qwen2.5-Omni專為全面的多模態感知設計,能夠無縫處理包括文本、圖像、音頻和視頻在內的多種輸入形式。其獨特之處在于,能夠實時以流式方式響應,并同時生成文本和自然語音合成的輸出。這一特性使得Qwen2.5-Omni在交互體驗上達到了新的高度。
Qwen團隊此次引入了全新的Thinker-Talker架構,這一架構是Qwen2.5-Omni的核心創新之一。Thinker模塊如同大腦,負責處理多模態輸入,生成高層語義表征和對應文本內容;而Talker模塊則像發聲器官,接收Thinker實時輸出的語義表征和文本,以流式方式流暢合成離散語音單元。這種架構不僅提高了模型的處理效率,還保證了輸出的自然性和穩定性。
在實時音視頻交互方面,Qwen2.5-Omni同樣表現出色。其架構支持完全實時交互,能夠分塊輸入并即時輸出,為用戶提供了流暢無阻的交互體驗。Qwen2.5-Omni在語音生成的自然性和穩定性方面也超越了現有的許多流式和非流式替代方案。
在性能表現上,Qwen2.5-Omni同樣不容小覷。與同等規模的單模態模型相比,Qwen2.5-Omni在多模態任務中展現出了卓越的性能。在音頻能力上,它優于類似大小的Qwen2-Audio,并與Qwen2.5-VL-7B保持同等水平。同時,Qwen2.5-Omni在端到端語音指令跟隨方面也表現出色,與文本輸入處理的效果相媲美。
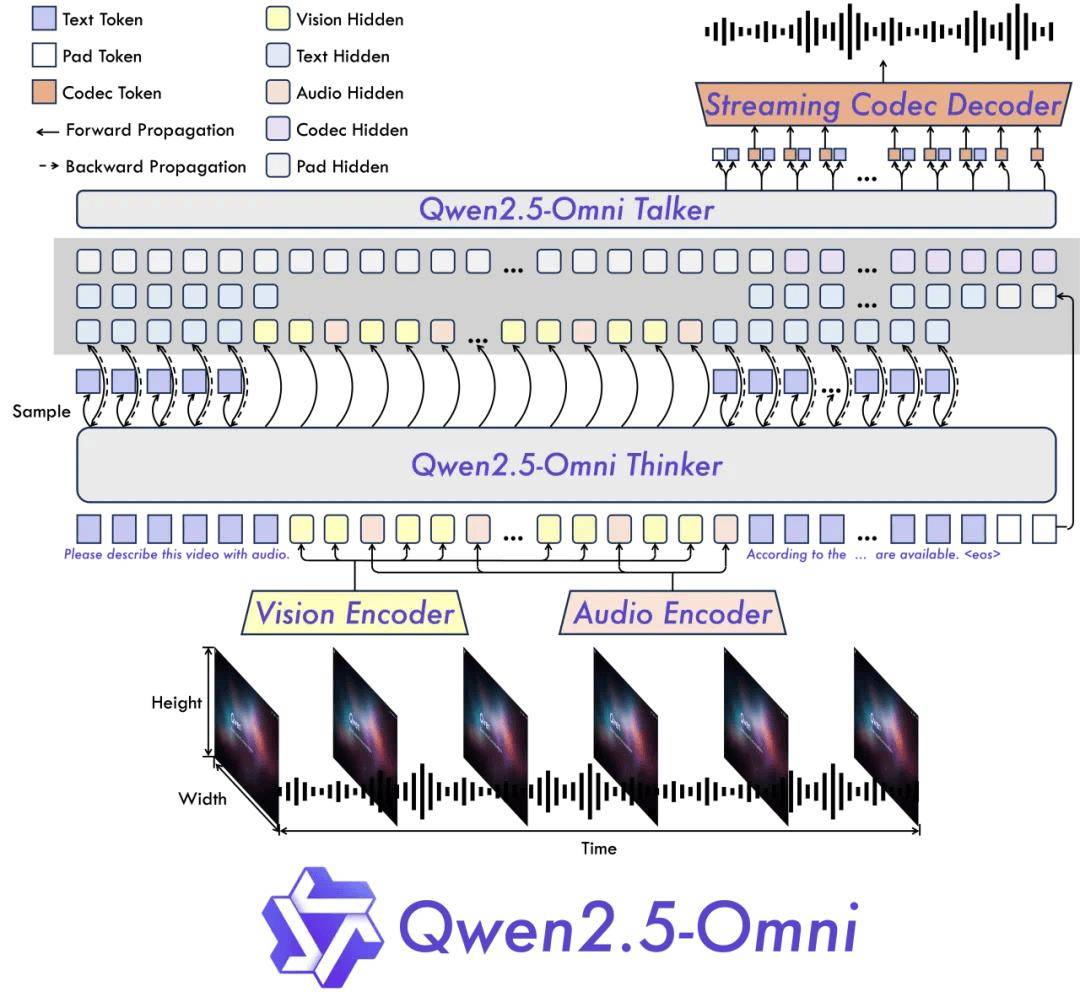
模型架構圖
為了更直觀地展示Qwen2.5-Omni的性能優勢,阿里云還提供了多個基準測試的結果。在多模態任務OmniBench中,Qwen2.5-Omni達到了SOTA(State-of-the-Art)的表現。在單模態任務中,Qwen2.5-Omni也在多個領域中表現優異,包括語音識別、翻譯、音頻理解、圖像推理、視頻理解以及語音生成等。
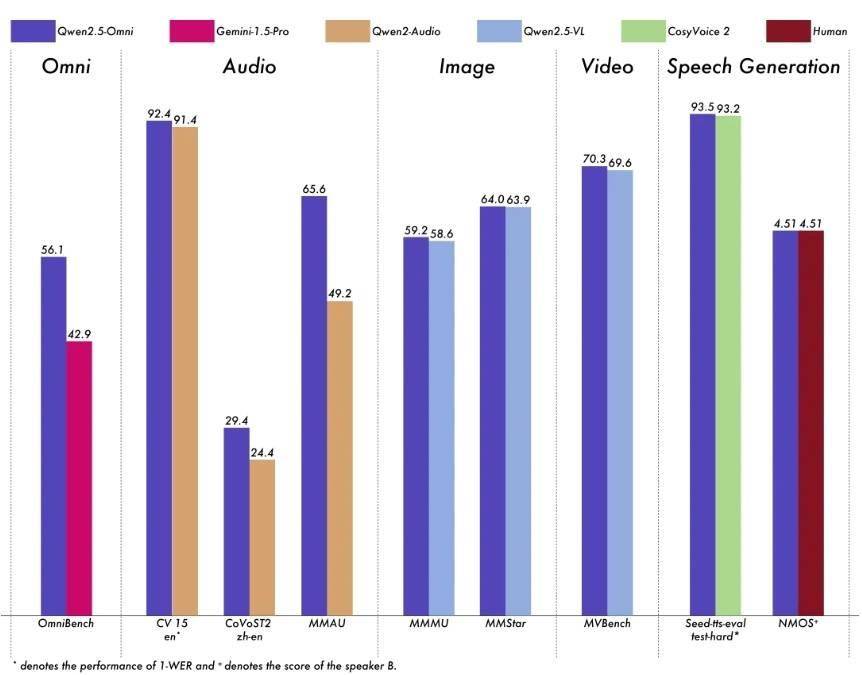
模型性能圖
對于開發者而言,Qwen2.5-Omni的開源無疑是一個巨大的福音。他們可以通過訪問Hugging Face、ModelScope、DashScope和GitHub等平臺,輕松獲取模型并進行二次開發。這不僅有助于推動人工智能技術的進一步發展,還為開發者提供了更多的創新機會。
如果你對Qwen2.5-Omni感興趣,不妨親自體驗一下。你可以通過訪問ModelScope平臺上的Qwen2.5-Omni Demo頁面,感受這款旗艦級多模態模型的強大魅力。