近日,科技界迎來了一項(xiàng)令人矚目的創(chuàng)新成果——微軟研究團(tuán)隊(duì)推出的開源大型語言模型BitNet b1.58 2B4T。這款模型以獨(dú)特的低精度架構(gòu)原生訓(xùn)練而成,擁有20億參數(shù),卻在計(jì)算資源需求上實(shí)現(xiàn)了大幅縮減。
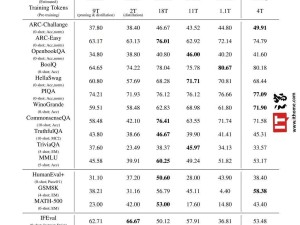
據(jù)技術(shù)報(bào)告顯示,BitNet b1.58 2B4T的性能直逼同規(guī)模的全精度模型。其非嵌入內(nèi)存占用僅為0.4GB,這一數(shù)據(jù)遠(yuǎn)低于競品Gemma-3 1B的1.4GB和MiniCPM 2B的4.8GB,展現(xiàn)了其卓越的內(nèi)存效率。
BitNet的高效秘訣在于其創(chuàng)新的架構(gòu)。該模型摒棄了傳統(tǒng)的16位數(shù)值,采用定制的BitLinear層,將權(quán)重限制為-1、0、+1三種狀態(tài),形成了三值系統(tǒng)。這種設(shè)計(jì)使得每權(quán)重僅需約1.58位信息存儲(chǔ),從而實(shí)現(xiàn)了高效的存儲(chǔ)和計(jì)算。
BitNet在層間激活值上也進(jìn)行了優(yōu)化,采用了8位整數(shù)量化,形成了W1.58A8的配置。同時(shí),微軟還對Transformer架構(gòu)進(jìn)行了調(diào)整,引入了平方ReLU激活函數(shù)、標(biāo)準(zhǔn)旋轉(zhuǎn)位置嵌入(RoPE)以及subln歸一化等技術(shù),確保了低位訓(xùn)練的穩(wěn)定性。這種原生1位訓(xùn)練的方式避免了傳統(tǒng)后訓(xùn)練量化(PTQ)可能帶來的性能損失。
BitNet b1.58 2B4T的開發(fā)歷經(jīng)了三個(gè)階段。首先,基于4萬億token的網(wǎng)絡(luò)數(shù)據(jù)、代碼和合成數(shù)學(xué)數(shù)據(jù)集進(jìn)行了預(yù)訓(xùn)練。隨后,通過公開及合成指令數(shù)據(jù)集進(jìn)行了監(jiān)督微調(diào)(SFT),如WizardLM Evol-Instruct等。最后,采用直接偏好優(yōu)化(DPO)方法,利用UltraFeedback等數(shù)據(jù)集提升了模型的對話能力和安全性。
微軟的測試結(jié)果顯示,BitNet在GSM8K(數(shù)學(xué))、PIQA(物理常識(shí))等基準(zhǔn)測試中表現(xiàn)優(yōu)異,整體性能與主流1B-2B參數(shù)的全精度模型相當(dāng)。同時(shí),在能耗和CPU解碼延遲上也占據(jù)了顯著優(yōu)勢,每token能耗僅為0.028焦耳,CPU解碼延遲為29毫秒。

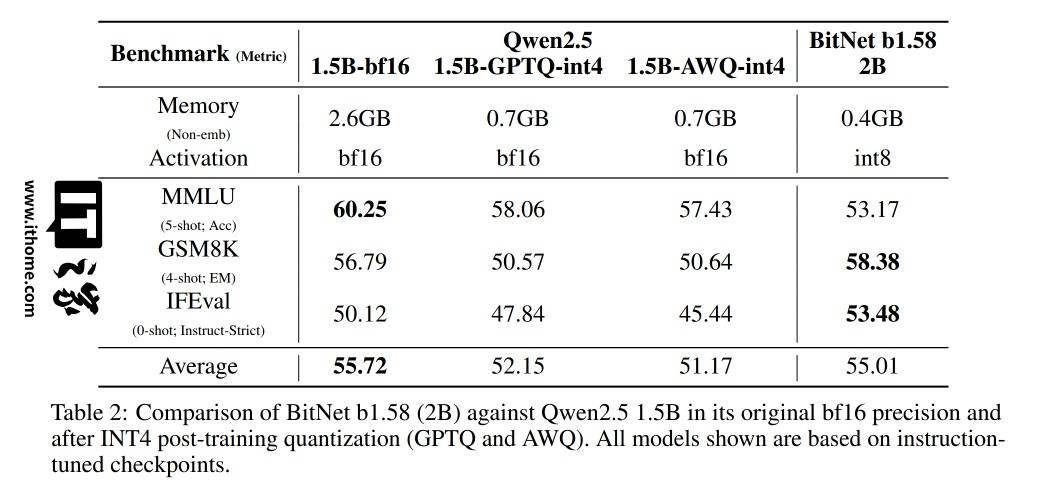
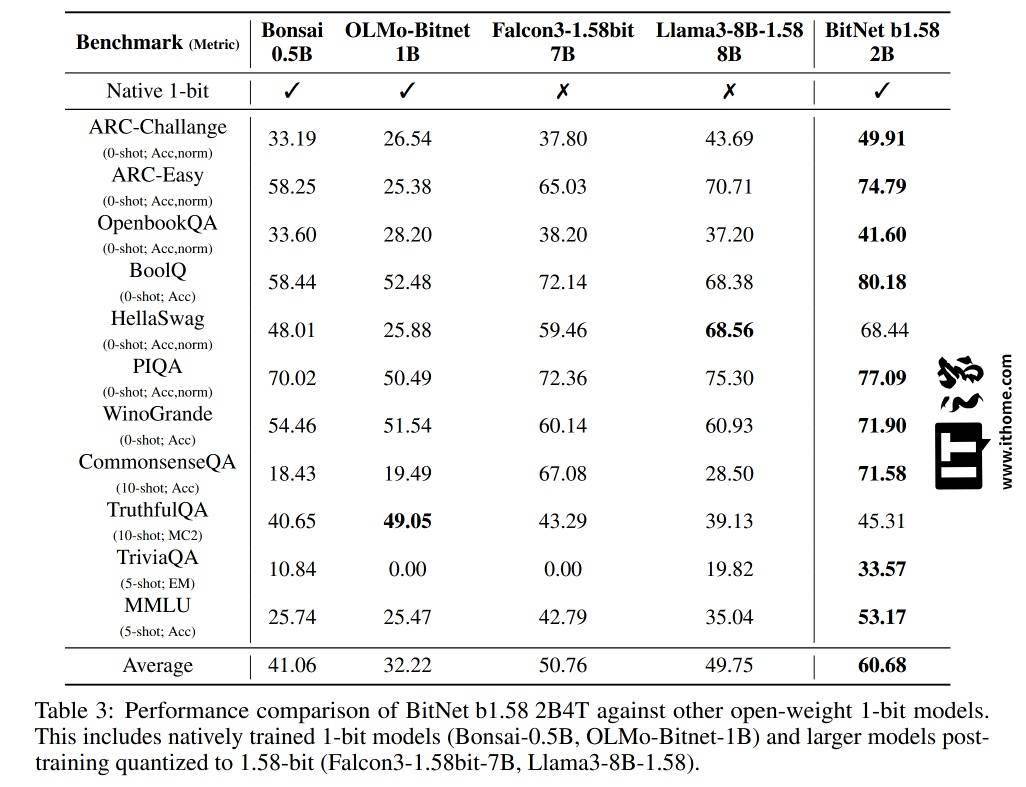
然而,值得注意的是,BitNet的高效性需要依賴微軟提供的專用C++框架bitnet.cpp來實(shí)現(xiàn)。如果使用標(biāo)準(zhǔn)工具如Hugging Face transformers庫,則無法充分展現(xiàn)其速度和能耗優(yōu)勢。
微軟還透露了未來的計(jì)劃,包括優(yōu)化GPU和NPU支持,延長上下文窗口至4096 token,并探索更大規(guī)模的模型、多語言功能以及硬件協(xié)同設(shè)計(jì)。目前,BitNet b1.58 2B4T已經(jīng)以MIT許可證在Hugging Face上發(fā)布,供社區(qū)進(jìn)行測試和應(yīng)用。