近期,科技界傳來一項令人矚目的新進展。據(jù)科技媒體marktechpost報道,加州大學伯克利分校的一支研究團隊在人工智能領(lǐng)域取得了突破,他們開發(fā)了一種創(chuàng)新的訓練方法,能夠顯著提升大語言模型(LLM)的推理能力,而這一過程僅需要少量的數(shù)據(jù)。
長久以來,提升LLM的推理能力一直是科研人員面臨的重大挑戰(zhàn)。傳統(tǒng)上,為了訓練模型生成具有結(jié)構(gòu)化自反思、驗證和回溯的長鏈式思維(CoT)響應(yīng),往往需要在龐大的數(shù)據(jù)集上進行長時間的微調(diào),且許多專有模型的訓練方法并不公開,這無疑增加了研究的難度。
然而,這支研究團隊卻另辟蹊徑,他們提出的新方法僅使用了17000個CoT示例,對Qwen2.5-32B-Instruct模型進行了微調(diào),并結(jié)合了SFT和LoRA技術(shù)。這一方法的核心理念在于優(yōu)化推理步驟的結(jié)構(gòu)完整性,而非內(nèi)容本身,通過改進邏輯一致性并減少不必要的計算開銷,從而實現(xiàn)了LLM推理效率的顯著提升。
研究表明,CoT的結(jié)構(gòu)在增強LLM推理性能方面起著至關(guān)重要的作用。研究團隊發(fā)現(xiàn),改變訓練數(shù)據(jù)的邏輯結(jié)構(gòu)會顯著影響模型的準確性,而單個推理步驟的修改則對整體影響較小。這一發(fā)現(xiàn)為進一步優(yōu)化LLM的推理能力提供了重要的理論依據(jù)。

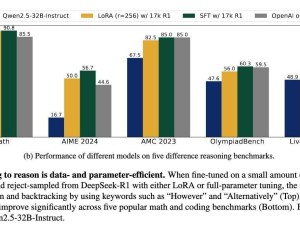
為了驗證這一新方法的有效性,研究團隊進行了多項測試。測試結(jié)果顯示,在使用新方法后,LLM在多個基準測試上的表現(xiàn)均取得了顯著提升。例如,在AIME 2024測試中,準確率從基線水平大幅提升至56.7%;在LiveCodeBench測試中,得分提高了8.1個百分點;在Math-500測試中,達到了90.8%的高準確率;在AMC 2023和OlympiadBench測試中,也分別取得了85.0%和60.3%的優(yōu)異成績。
這些令人矚目的測試結(jié)果表明,這種高效的微調(diào)技術(shù)使得LLM在更少的數(shù)據(jù)需求下,能夠達到與OpenAI的o1-preview等專有模型相媲美的推理能力。這一突破不僅為人工智能領(lǐng)域的研究開辟了新的道路,也為未來LLM在實際應(yīng)用中的廣泛推廣奠定了堅實的基礎(chǔ)。