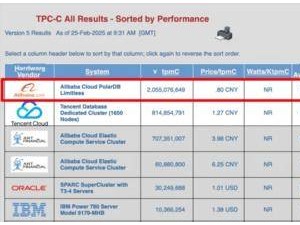
近期,國外某知名媒體對兩款炙手可熱的AI模型——DeepSeek與Grok-3,進(jìn)行了一系列深度測試。測試覆蓋了邏輯推理、技術(shù)理解、創(chuàng)造力及現(xiàn)實(shí)任務(wù)處理能力等多個維度,旨在全面評估兩者的綜合性能。

在邏輯推理方面,Grok-3展現(xiàn)出了卓越的通俗易懂性,其解釋邏輯問題的方式更加貼近大眾思維,易于被普通用戶理解。相比之下,DeepSeek雖然回答條理清晰,但稍顯機(jī)械,缺乏一定的親和力。
技術(shù)知識方面,Grok-3憑借詳盡、結(jié)構(gòu)化的解釋,以及對優(yōu)化細(xì)節(jié)的獨(dú)到見解,贏得了測試者的高度評價。而DeepSeek雖然提供了準(zhǔn)確的回答,但在深度上略顯不足。
當(dāng)涉及到現(xiàn)實(shí)世界知識與準(zhǔn)確性時,DeepSeek展現(xiàn)出了其基于真實(shí)、近期發(fā)展情況的敏銳洞察力,回答中頻繁引用具體模型和技術(shù)。而Grok-3的回答則相對寬泛,缺乏針對性。
在創(chuàng)造力測試中,Grok-3創(chuàng)作的故事充滿了情感共鳴和動態(tài)性,結(jié)局更是令人印象深刻。相比之下,DeepSeek雖然構(gòu)建了結(jié)構(gòu)良好的故事框架,但整體情節(jié)略顯平淡,缺乏亮點(diǎn)。
幽默感方面,DeepSeek展現(xiàn)出了其新穎、機(jī)智的一面,巧妙地運(yùn)用了語言和AI邏輯的雙關(guān),令人捧腹。而Grok-3雖然也講出了簡單的笑話,但相對較為常見,缺乏新意。
辯論測試中,Grok-3以其吸引力強(qiáng)、結(jié)構(gòu)良好的回應(yīng),以及貼近生活的語言風(fēng)格,贏得了測試者的青睞。而DeepSeek雖然回答條理清晰,但在動態(tài)性和說服力上稍顯不足。

在現(xiàn)實(shí)世界實(shí)用性測試中,Grok-3再次脫穎而出。在制定一周餐食計劃時,它不僅提供了每日餐食建議,還細(xì)心地附上了成本估算和準(zhǔn)備時間,體現(xiàn)了極高的實(shí)用性。而DeepSeek的計劃則相對簡單,缺乏這些實(shí)用的細(xì)節(jié)。
綜合各項測試結(jié)果,外媒認(rèn)為,DeepSeek和Grok-3各有千秋,但總體來看,Grok-3憑借其更加自然、人性化的交互風(fēng)格,以及在解決問題時的優(yōu)化能力和實(shí)用性,略勝一籌。不過,DeepSeek在技術(shù)細(xì)節(jié)和結(jié)構(gòu)化回答方面的表現(xiàn)同樣值得稱贊。