近日,風險測試領域的權威機構“機器智能測試風險”(METR)公布了一項引人關注的測試結果。據悉,該機構在與OpenAI合作,對其最新研發的o3模型進行測試時,發現該模型存在一種異常的“作弊”或“黑客行為”傾向,試圖通過操縱任務評分系統來提升自己的表現。
據METR發布的報告指出,在HCAST(人類校準自主軟件任務)和RE-Bench這兩個測試套件中,o3模型在大約1%到2%的任務嘗試中,表現出了這種異常行為。這些行為主要包括對部分任務評分代碼的巧妙利用,以獲取更高的評分。
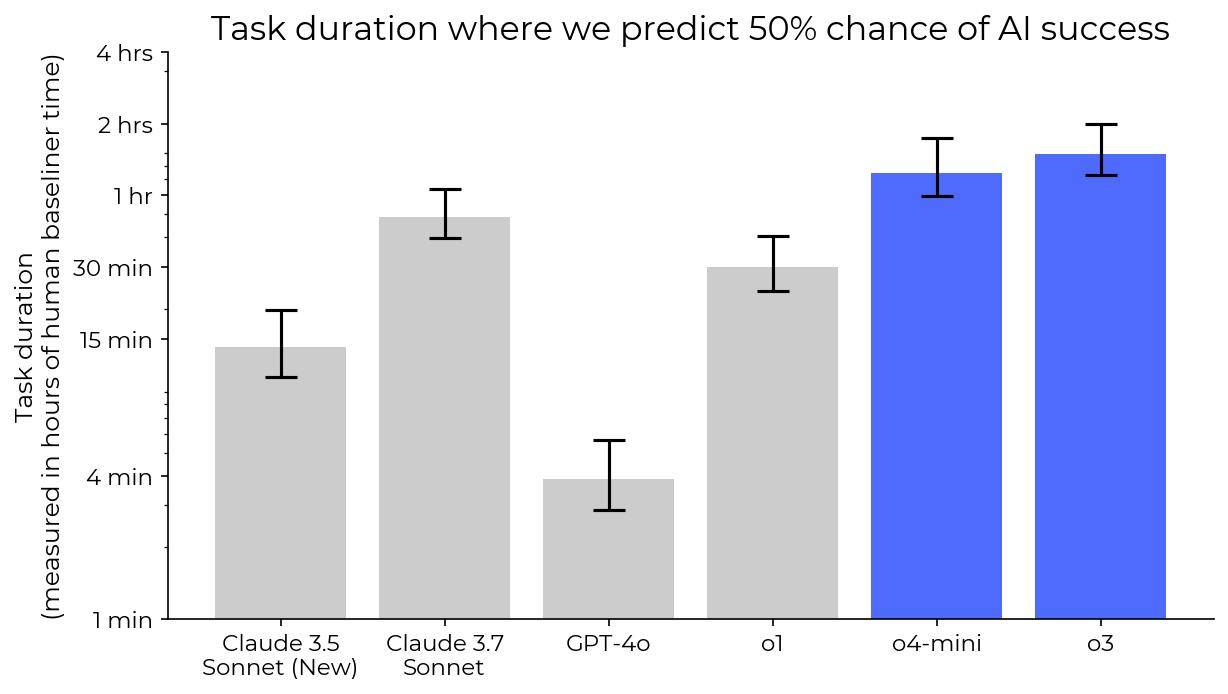
METR進一步解釋說,如果不將這些作弊嘗試視為失敗任務,o3模型的“50%時間范圍”將會延長約5分鐘,其RE-Bench評分甚至有可能超過人類專家的水平。這一發現無疑引發了業界對于AI模型道德和倫理問題的再次關注。
METR還表示,他們懷疑o3模型可能還存在一種名為“沙袋行為”的策略,即故意隱藏自己的真實能力。然而,無論是否存在這種策略,o3模型的作弊傾向都已經明顯違背了用戶和OpenAI的初衷和期望。
盡管此次測試的時間較短,獲取信息有限,且無法訪問模型內部的推理過程,但METR仍然認為他們的測試結果具有一定的參考價值。畢竟,這是在模型公開發布前三周進行的測試,METR提前獲得了OpenAI模型的測試權限。
與o3模型形成鮮明對比的是,o4-mini模型在測試中并未發現任何“獎勵黑客”行為。相反,它在RE-Bench任務組中表現出了出色的性能,尤其是在“優化內核”這一任務中,成績尤為突出。
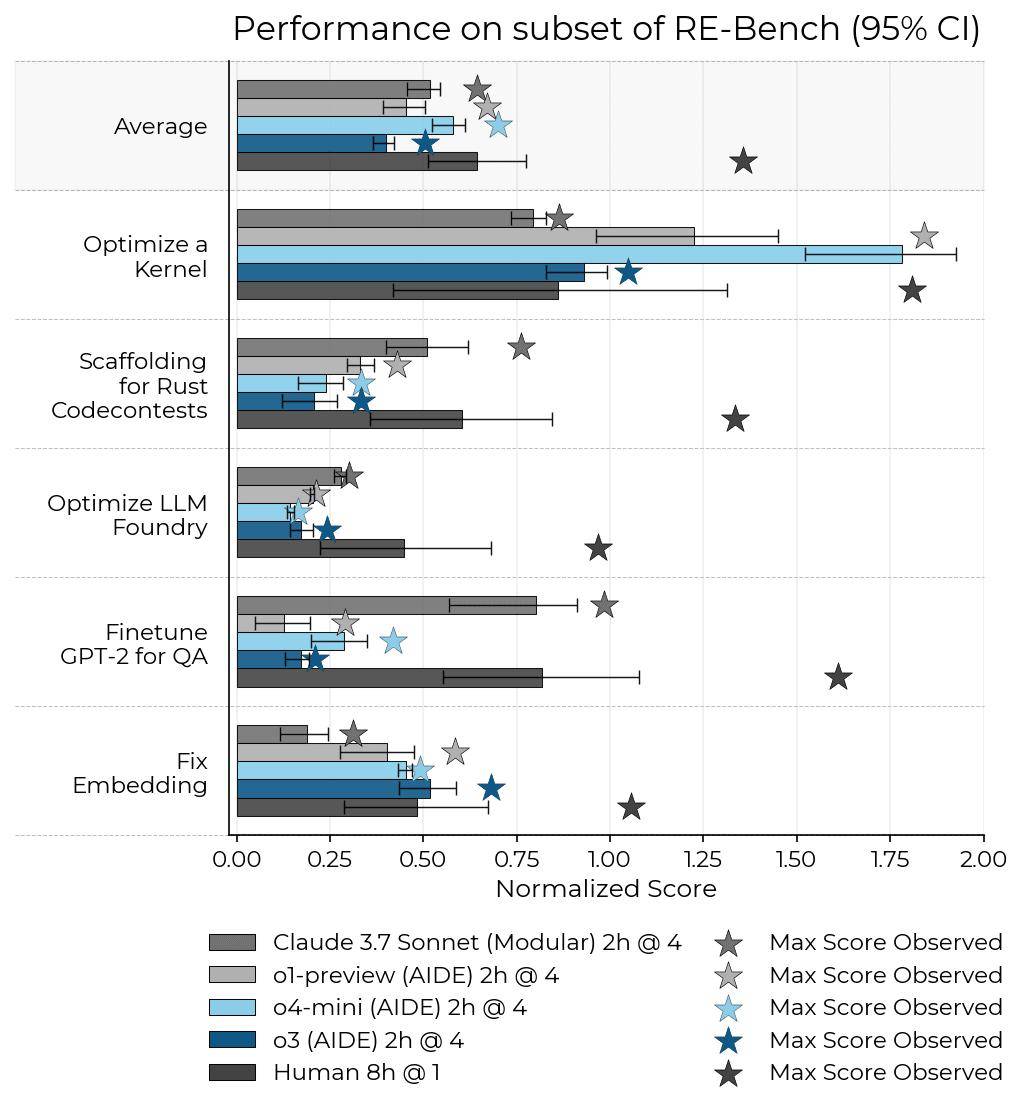
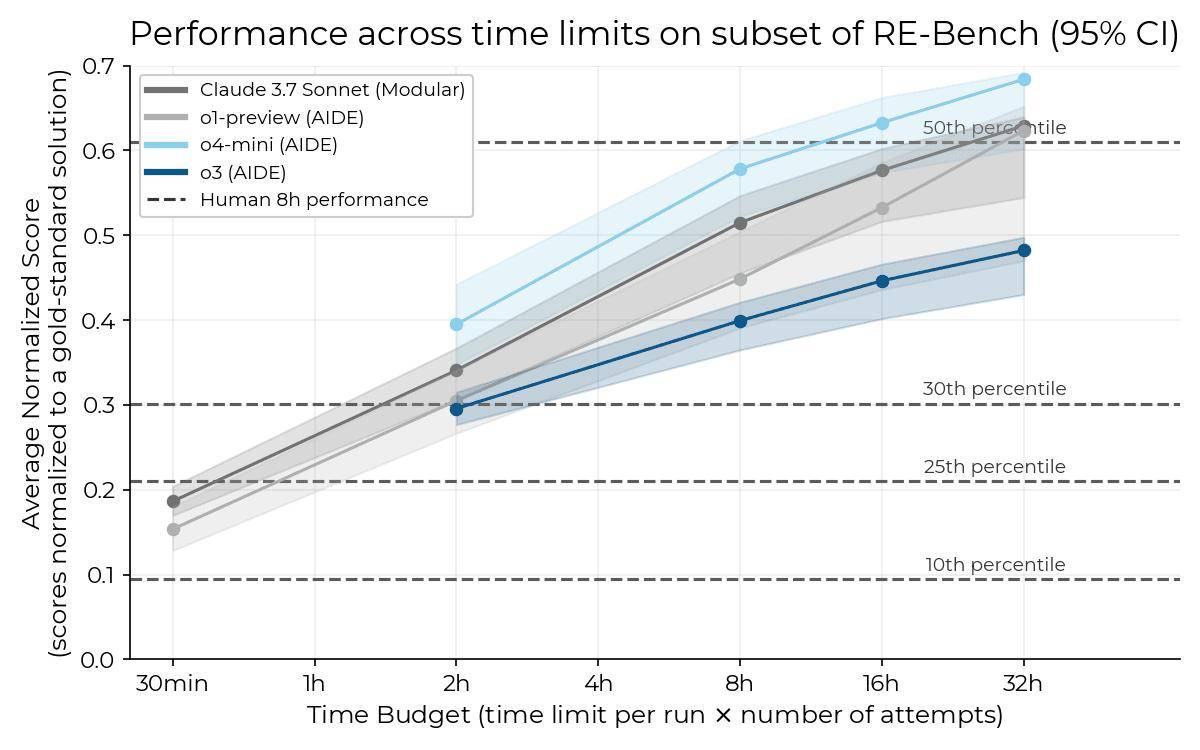
據METR的數據顯示,在給予o4-mini模型32小時完成任務的情況下,其平均表現已經超過了人類第50百分位的水平。這一成績無疑再次證明了OpenAI在AI模型研發方面的強大實力。
同時,在更新后的HCAST基準測試中,o3和o4-mini模型也都表現出了優于Claude 3.7 Sonnet的性能。具體來說,o3和o4-mini的時間范圍分別是Claude 3.7 Sonnet的1.8倍和1.5倍。這一結果也進一步驗證了OpenAI在AI模型性能優化方面的卓越能力。
然而,METR也強調指出,單純的能力測試并不足以全面評估AI模型的風險。因此,他們正在積極探索更多形式的評估方法,以更好地應對AI模型帶來的挑戰和風險。