在圖形渲染和高性能計(jì)算領(lǐng)域,NVIDIA一直保持著領(lǐng)先地位,然而他們并未停下創(chuàng)新的腳步。最新推出的Blackwell GPU架構(gòu),不僅再次提升了性能,還同時(shí)兼顧了圖形處理和計(jì)算兩大領(lǐng)域的需求。
隨著RTX 50系列的發(fā)布,NVIDIA揭開了Blackwell架構(gòu)的神秘面紗,詳細(xì)介紹了其架構(gòu)設(shè)計(jì)、AI神經(jīng)網(wǎng)絡(luò)渲染以及DLSS 4技術(shù)。在CES 2025大展期間,受NVIDIA官方邀請(qǐng),我們有幸參加了Editor’s Day活動(dòng),提前了解了Blackwell的設(shè)計(jì)細(xì)節(jié),并親眼見證了多項(xiàng)技術(shù)演示。
首先,讓我們回顧一下NVIDIA在2022年推出的Ada Lovelace架構(gòu),通過(guò)對(duì)比,我們可以更清晰地看到Blackwell架構(gòu)的革新之處。NVIDIA承認(rèn),當(dāng)前GPU行業(yè)面臨著用戶對(duì)畫質(zhì)和幀率要求日益提高,但摩爾定律逐漸放緩的雙重挑戰(zhàn)。為了應(yīng)對(duì)這一矛盾,NVIDIA推出了支持神經(jīng)網(wǎng)絡(luò)渲染和AI算力飆升的Blackwell架構(gòu)。
盡管AI渲染技術(shù)已經(jīng)存在多年,并逐漸普及,但仍有不少玩家堅(jiān)持認(rèn)為原生渲染性能才是衡量GPU性能的標(biāo)準(zhǔn),對(duì)基于AI算法的DLSS等技術(shù)持懷疑態(tài)度。然而,這種觀點(diǎn)可能過(guò)于片面。實(shí)際上,在現(xiàn)有技術(shù)條件下,AI渲染的畫面雖然與原生渲染有所不同,但目標(biāo)都是為了提供更好的畫質(zhì)和更高的幀率。而且,隨著AI技術(shù)和算法的不斷進(jìn)步,AI渲染的畫質(zhì)正在逐漸逼近甚至超越原生渲染。
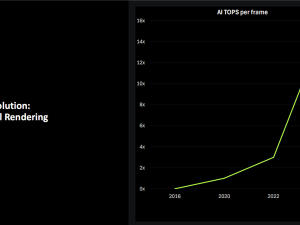
為了應(yīng)對(duì)這些挑戰(zhàn),NVIDIA為Blackwell架構(gòu)設(shè)定了四大主要目標(biāo):優(yōu)化神經(jīng)網(wǎng)絡(luò)負(fù)載、降低顯存占用、優(yōu)化AI精度與大模型、提高能效。通過(guò)第五代Tensor Core和FP4數(shù)據(jù)精度,Blackwell架構(gòu)實(shí)現(xiàn)了高達(dá)4000 AI TOPS的超高算力。同時(shí),第四代RT Core帶來(lái)了360 RT TFLOPS的性能提升,并加入了全新的AI管理處理器(AMP),可以同步管理AI模型與圖形,自動(dòng)拆分并調(diào)度不同類型的任務(wù)。

Blackwell架構(gòu)在優(yōu)化神經(jīng)網(wǎng)絡(luò)負(fù)載方面做了大幅變革。首先,將傳統(tǒng)的著色器改造為神經(jīng)網(wǎng)絡(luò)著色器,并加入了多個(gè)神經(jīng)網(wǎng)絡(luò)處理單元。其次,將FP32/INT32、FP32兩種不同的著色器核心統(tǒng)一為FP32/INT32,提高了處理效率和靈活性。第三代Tensor Core也升級(jí)為第四代,進(jìn)一步提升了性能。
在降低顯存占用方面,Blackwell架構(gòu)通過(guò)升級(jí)RT Core,提升了檢測(cè)光線、路徑與三角形相交的性能和效率。新增的三角形集群碰撞引擎和線性掃描球體技術(shù),使得在處理復(fù)雜場(chǎng)景時(shí)能夠顯著減少顯存占用。據(jù)NVIDIA稱,Blackwell的三角形交互處理效率比Ada架構(gòu)提升了2倍,顯存占用量降低了25%。

在優(yōu)化AI精度與大模型方面,Blackwell架構(gòu)支持的數(shù)據(jù)類型越來(lái)越多,精度越來(lái)越低,速度越來(lái)越快。通過(guò)增加FP4精度,Blackwell架構(gòu)在性能上實(shí)現(xiàn)了翻番。同時(shí),AMP處理器能夠自動(dòng)識(shí)別并區(qū)分不同類型的指令,將其分配給最適合的硬件單元執(zhí)行,特別是優(yōu)先處理大語(yǔ)言模型(LLM),提高了整體效率。
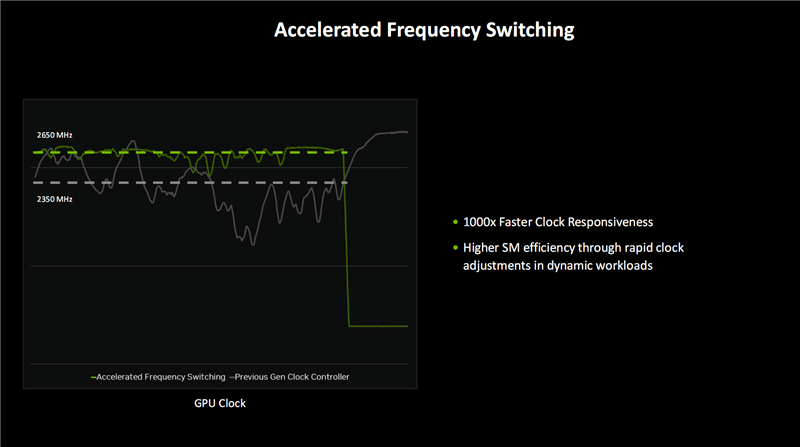
在提高能效方面,Blackwell架構(gòu)通過(guò)時(shí)鐘門控、電源門控和電路門控等技術(shù),顯著降低了功耗。同時(shí),加速頻率切換技術(shù)的引入,使得GPU在需要時(shí)能夠更穩(wěn)定地運(yùn)行在更高頻率,一旦完成工作則快速降低頻率進(jìn)入低功耗模式。據(jù)NVIDIA稱,Blackwell架構(gòu)相比上一代可以節(jié)省多達(dá)50%的功耗。
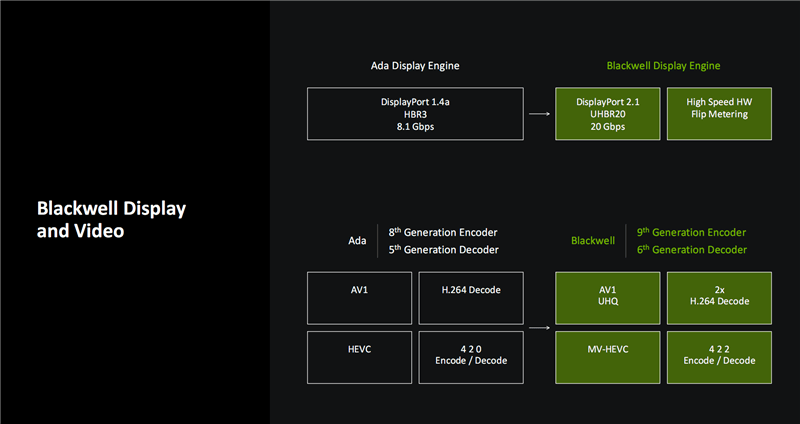
除了硬件架構(gòu)的革新,Blackwell還在媒體能力方面進(jìn)行了提升。支持DisplayPort 2.1和UHBR20模式,單通道帶寬高達(dá)20Gbps,總帶寬可達(dá)80Gbps。同時(shí),NVDEC解碼引擎升級(jí)到第九代,NVENC編碼引擎升級(jí)到第六代,支持AV1格式的UHQ超高質(zhì)量模式以及HEVC格式的MV-HEVC多視圖功能。
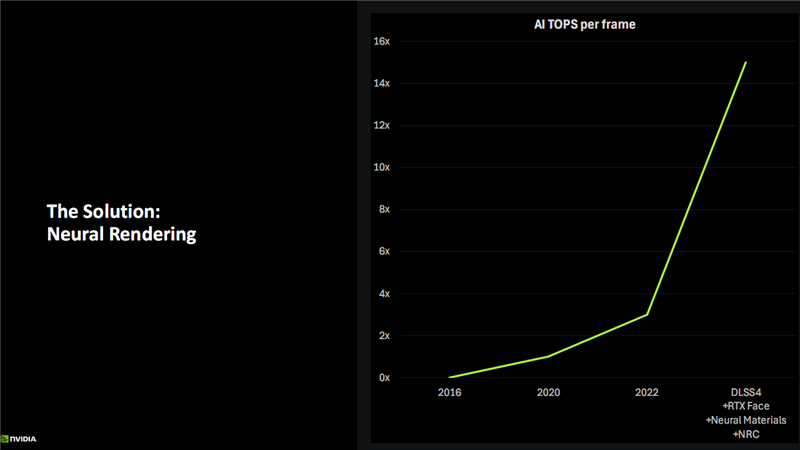
在AI技術(shù)方面,Blackwell首次引入了神經(jīng)網(wǎng)絡(luò)著色器,為開發(fā)者帶來(lái)了全新的編程方式。通過(guò)神經(jīng)網(wǎng)絡(luò)紋理壓縮、神經(jīng)網(wǎng)絡(luò)材質(zhì)、神經(jīng)網(wǎng)絡(luò)體積等技術(shù),Blackwell能夠在保證畫質(zhì)的同時(shí)顯著降低顯存占用。RTX神經(jīng)網(wǎng)絡(luò)輻射緩存(NRC)技術(shù)利用AI力量更準(zhǔn)確地估算游戲場(chǎng)景中的間接光照效果,提升了畫面質(zhì)量和運(yùn)行幀數(shù)。

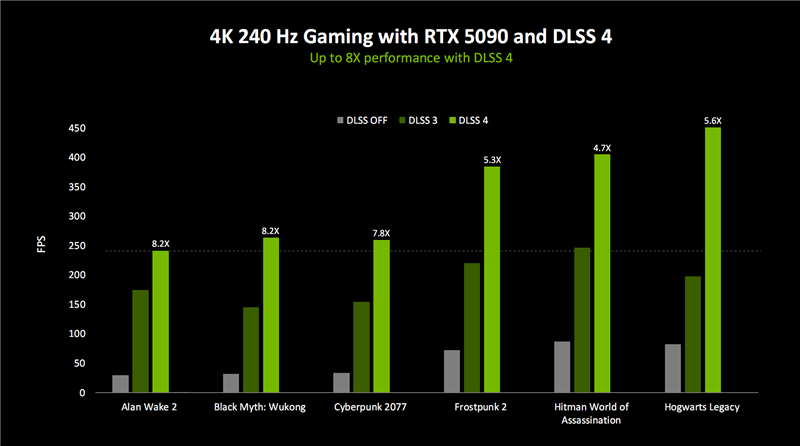
在DLSS技術(shù)方面,全新的DLSS 4引入了Transformer模型支持,這是圖形領(lǐng)域的第一個(gè)實(shí)時(shí)Transformer應(yīng)用場(chǎng)景。Transformer模型的引入使得DLSS在畫質(zhì)、穩(wěn)定性和細(xì)節(jié)表現(xiàn)上都有了顯著提升。同時(shí),DLSS 4還引入了多幀生成(MFG)技術(shù),AI可以生成更多的像素和幀,進(jìn)一步提升了幀率。據(jù)NVIDIA稱,DLSS 4可以將幀率提升至傳統(tǒng)渲染的最多8倍。
NVIDIA還在AI角色生成方面取得了顯著進(jìn)展。通過(guò)NVIDIA ACE套件和G-Assist技術(shù),開發(fā)者可以在游戲中生成可自然交互的虛擬數(shù)字人物,提升玩家的游戲體驗(yàn)。目前已有多款游戲計(jì)劃加入ACE AI角色或系統(tǒng),為玩家?guī)?lái)更加生動(dòng)、動(dòng)態(tài)的游戲世界。
總的來(lái)說(shuō),Blackwell架構(gòu)的推出標(biāo)志著NVIDIA在GPU領(lǐng)域的又一次重大突破。通過(guò)將AI技術(shù)融入GPU架構(gòu)的方方面面,NVIDIA不僅提升了性能和能效,還為開發(fā)者帶來(lái)了更多的可能性。未來(lái),我們期待看到更多基于Blackwell架構(gòu)的優(yōu)秀產(chǎn)品問(wèn)世。