近期,豆包大模型團隊低調推出的Seedream2.0圖像生成模型,在業界引發了廣泛關注。這款模型不僅在中英文雙語理解與文字渲染方面表現突出,還已經在豆包和即夢等應用中得以應用。隨著該模型的技術細節在arXiv平臺上的正式公布,其背后的創新技術也得以公之于眾。
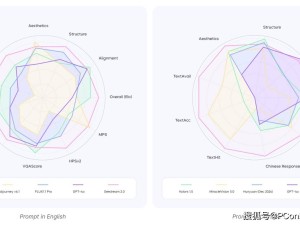
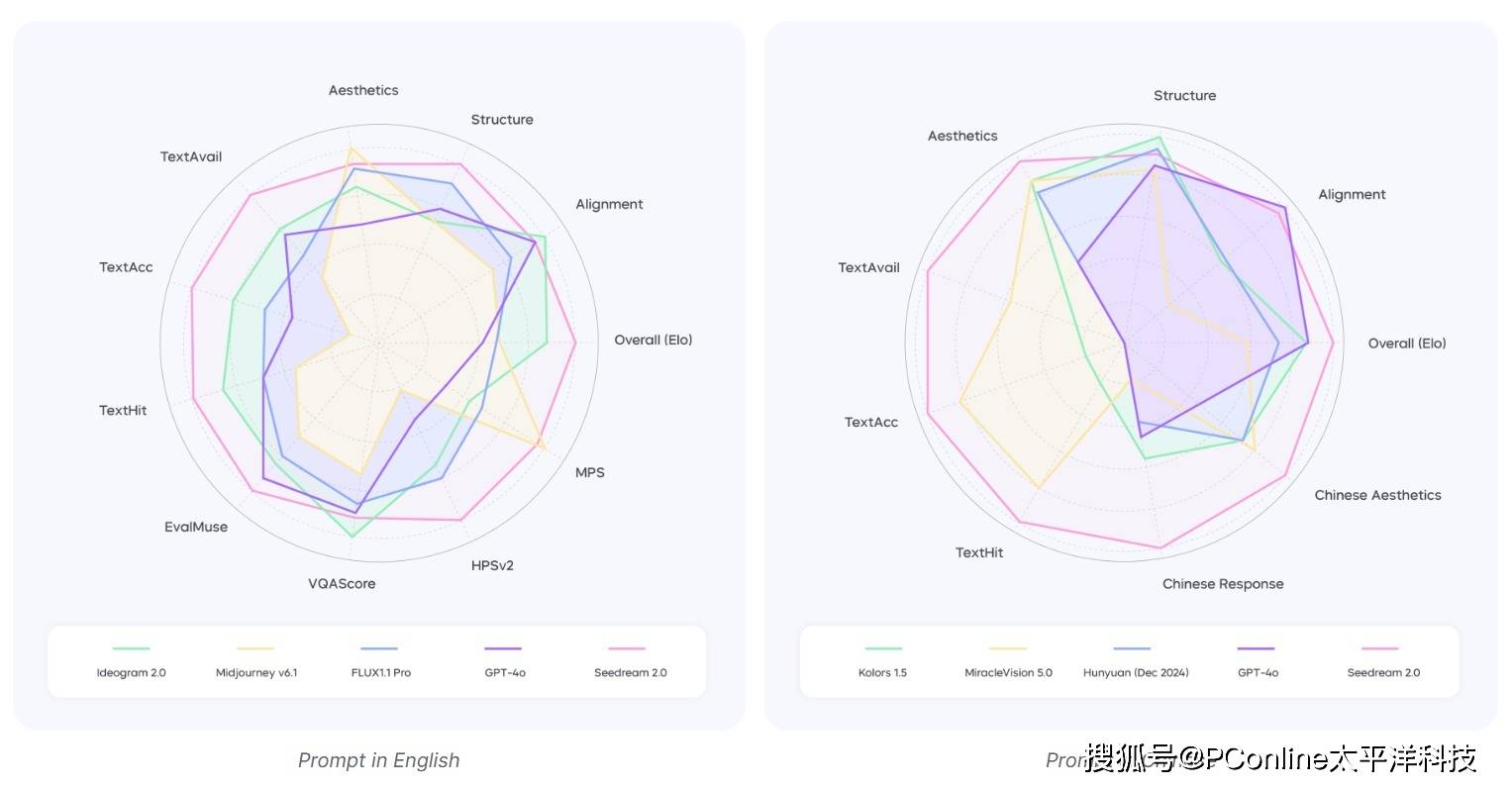
相較于Midjourney等主流圖像生成模型,Seedream2.0的顯著優勢在于其雙語解析和文字渲染能力。它不僅能夠直接理解中文提示詞進行圖像渲染,還能精準地輸出中英文文字。在一系列針對主流文生圖模型的測試中,Seedream2.0在多個維度上均超越了當前最先進的模型,特別是在中文文化細節和文本渲染方面,其表現尤為卓越。
通過幾個實際案例,我們可以更加直觀地感受到Seedream2.0的強大能力。例如,在一張使用中文Prompt生成的照片中,一只橙色虎斑貓特寫鏡頭下,貓咪抬起前爪,眼神中充滿好奇,仿佛即將采取行動。背景是藍天白云與耀眼陽光,前景則是綠色草地,太陽逆光效果營造出高對比度,整體風格超寫實,景深效果自然,背景還帶有輕微的動態模糊。這些細節的處理都極為到位,使得整個畫面看起來栩栩如生。
Seedream2.0在漢字渲染方面也展現出了不俗的實力。使用該模型渲染的漢字“貓”,并添加毛筆字效果,雖然筆畫上存在一些不符合書寫邏輯的地方,但整體上仍然能夠清晰地辨認出是“貓”字,且國風水墨畫的氛圍感十足。
Seedream2.0之所以能夠實現如此出色的圖像渲染效果,離不開其先進的擴散式Transformer架構。該架構中的每個Transformer模塊都包含一個自注意力層,能夠同時處理圖像和文本信息。針對圖像和文本的不同特性,模型還采用了不同的多層感知機(MLP)進行處理,并通過自適應層歸一化來調節每個注意力和MLP層。
在文本編碼方面,Seedream2.0通過將文本和圖像配對的數據用于微調大型語言模型(LLM),顯著增強了其雙語處理能力和理解復雜指令的能力。同時,為了準確編碼渲染文本的字形內容,模型還采用了ByT5字形對齊模型,確保與文本提示的一致性。
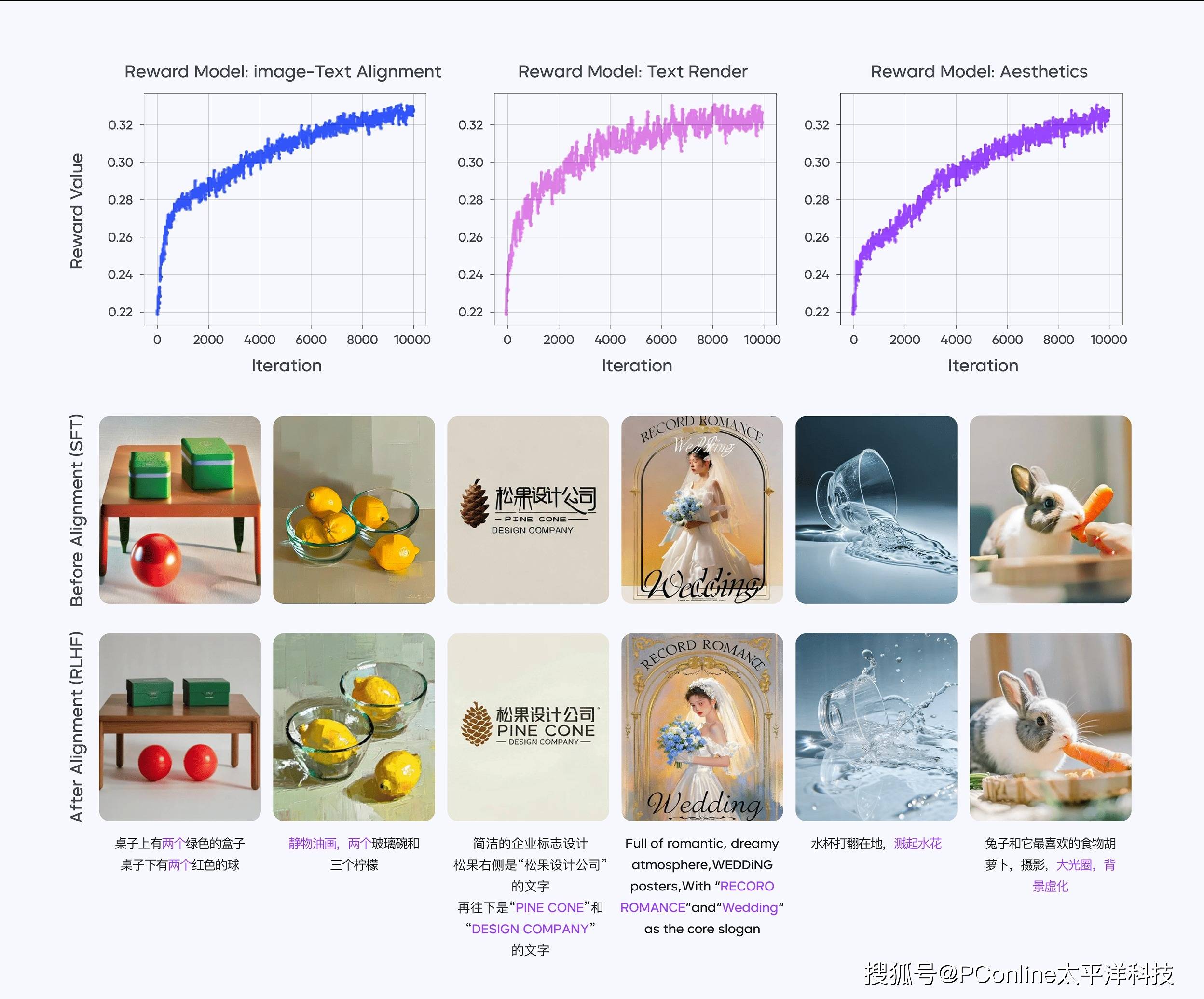
在模型訓練過程中,Seedream2.0團隊采用了多階段的方法。首先進行繼續訓練(CT)和監督微調(SFT),以提升模型的美學效果。隨后,通過自研的獎勵模型和反饋學習算法進行人類反饋對齊(RLHF),顯著改善了模型在各方面的整體表現。團隊還利用精調的大型語言模型(LLM)進行提示工程(PE),進一步提高了模型在美學和多樣性方面的表現。最后,開發了精修模型以提高基礎模型生成圖像的分辨率,并修正一些細微的結構性錯誤。
特別是在RLHF階段,Seedream2.0團隊引入了專為擴散模型設計的優化過程,包括偏好數據、獎勵模型和反饋學習算法。這一階段在提升模型的圖文一致性、美學效果、結構正確性和文本渲染等方面發揮了至關重要的作用。
自Seedream2.0發布以來,用戶普遍反映該模型在中英雙語解析、圖像細節呈現和文字渲染方面表現出色。技術細節的公開進一步驗證了其在數據處理和訓練優化上的先進性,也為廣大中文用戶提供了更多信心。對于廣大中文用戶而言,Seedream2.0無疑是一款比Midjourney更加貼合需求的國產大模型。