近日,科技界迎來了一項新的突破,meta AI與加州大學伯克利分校攜手推出了一個名為SWEET-RL的強化學習框架,并配套發布了CollaborativeAgentBench(簡稱ColBench)基準測試。這一合作旨在提升大語言模型(LLMs)在多輪人機協作任務中的性能,特別是在后端編程和前端設計兩大領域。
隨著大語言模型的發展,它們逐漸展現出執行復雜任務的潛力,但在多輪決策任務中仍面臨諸多挑戰。傳統的訓練方法主要依賴于單輪反饋或模仿高概率行為,這種方法在處理長期依賴和累積目標時顯得力不從心,導致模型在協作場景中表現平平,特別是在理解人類意圖和多步驟推理方面。
SWEET-RL框架的推出,正是為了解決這一難題。它采用了非對稱的“演員-評論家”結構,其中評論家在訓練過程中能夠訪問額外信息(如正確答案),從而更準確地評估演員的決策。這一創新不僅簡化了信用分配過程,還與LLMs的預訓練架構實現了更好的對齊。
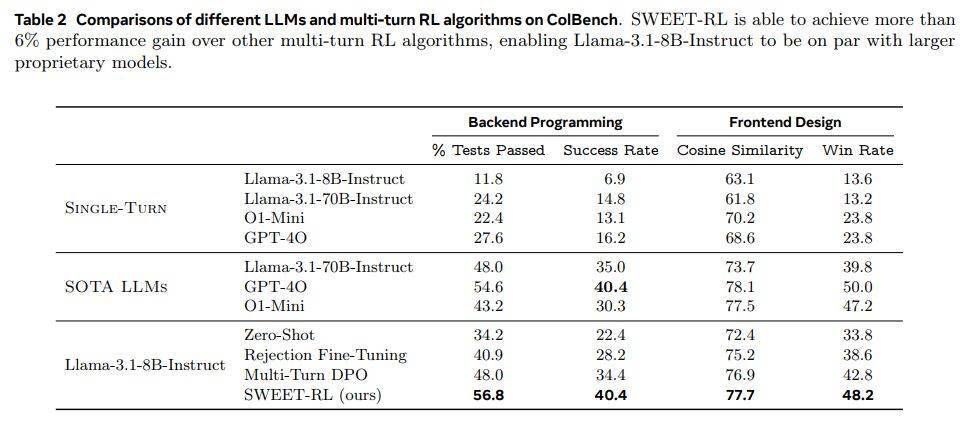
實驗結果顯示,SWEET-RL在后端編程任務中的通過率顯著提升至48.0%,在前端設計任務中的余弦相似度也達到了76.9%,這一成績顯著優于其他多輪強化學習方法。這一突破性的進展,無疑為LLMs在多輪人機協作任務中的應用開辟了新的道路。
為了更全面地評估SWEET-RL的性能,meta AI和加州大學伯克利分校還推出了ColBench基準測試。ColBench包含了超過10000個訓練任務和1000個測試案例,這些任務設計均模擬了真實的人機協作場景,涵蓋了后端編程(如Python函數編寫)和前端設計(如HTML代碼生成)兩大領域。該基準測試還限制了每輪交互的次數,最多不超過10次。
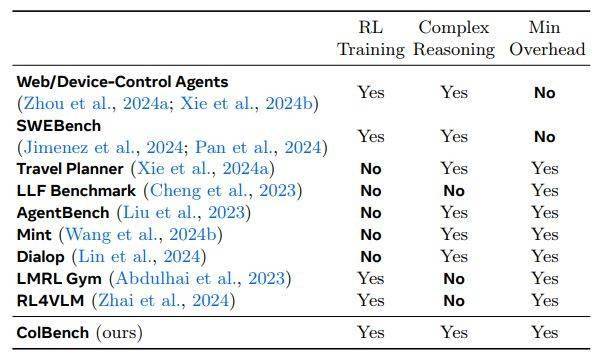
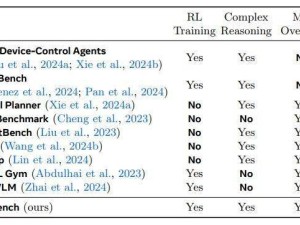
ColBench基準測試通過單元測試通過率和余弦相似度兩個指標來評估模型的性能,為多輪任務提供了可靠的評估標準。這一測試平臺的推出,不僅有助于研究人員更準確地評估SWEET-RL的性能,也為未來LLMs在多輪人機協作任務中的發展提供了有力的支持。