近日,一項名為framePack的創新技術橫空出世,為AI視頻生成領域帶來了革命性的突破。這項技術由GitHub的Lvmin Zhang與斯坦福大學的Maneesh Agrawala攜手打造,成功實現了視頻擴散模型的實用化,極大地提升了處理效率,使得在較低硬件配置下生成高質量長視頻成為可能。
framePack是一種全新的神經網絡架構,其核心優勢在于采用了多階段優化技術,有效降低了AI視頻生成任務對硬件的需求。通過利用固定長度的時域上下文,framePack能夠顯著減少GPU的顯存開銷,使得在僅6GB顯存的情況下,也能生成長達60秒的視頻片段。這一突破性的成果得益于framePack獨特的幀壓縮技術,它能夠對幀進行智能壓縮,并匯集到固定大小的上下文長度內,從而確保了高效的顯存利用。

傳統的視頻擴散模型在生成視頻時,需要處理大量的先前生成的帶噪幀數據,以預測下一個噪聲更少的幀。這一過程中,所參考的輸入幀數量會隨著視頻長度的增加而增長,導致顯存需求極高。而framePack則通過其創新的架構,成功解決了這一問題。它不僅能夠降低顯存消耗,還能在不顯著犧牲保真度的情況下,支持生成更長的視頻內容。
framePack還結合了緩解“漂移”現象的技術。這一技術能夠解決視頻質量隨長度增加而下降的問題,確保生成的視頻內容始終保持高質量。在硬件兼容性方面,framePack明確要求使用支持FP16和BF16數據格式的英偉達RTX 30、40或50系列GPU。對于其他品牌的硬件以及更早的英偉達顯卡,目前尚未得到驗證。但考慮到6GB顯存的需求,市面上大多數現代RTX顯卡都能滿足運行要求。
在性能方面,framePack同樣表現出色。以RTX 4090為例,在啟用teacache優化后,生成速度可達每秒約0.6幀。雖然實際速度會因顯卡型號的不同而有所差異,但framePack在生成過程中會逐幀顯示畫面,提供即時的視覺反饋,這一特性極大地提升了用戶體驗。
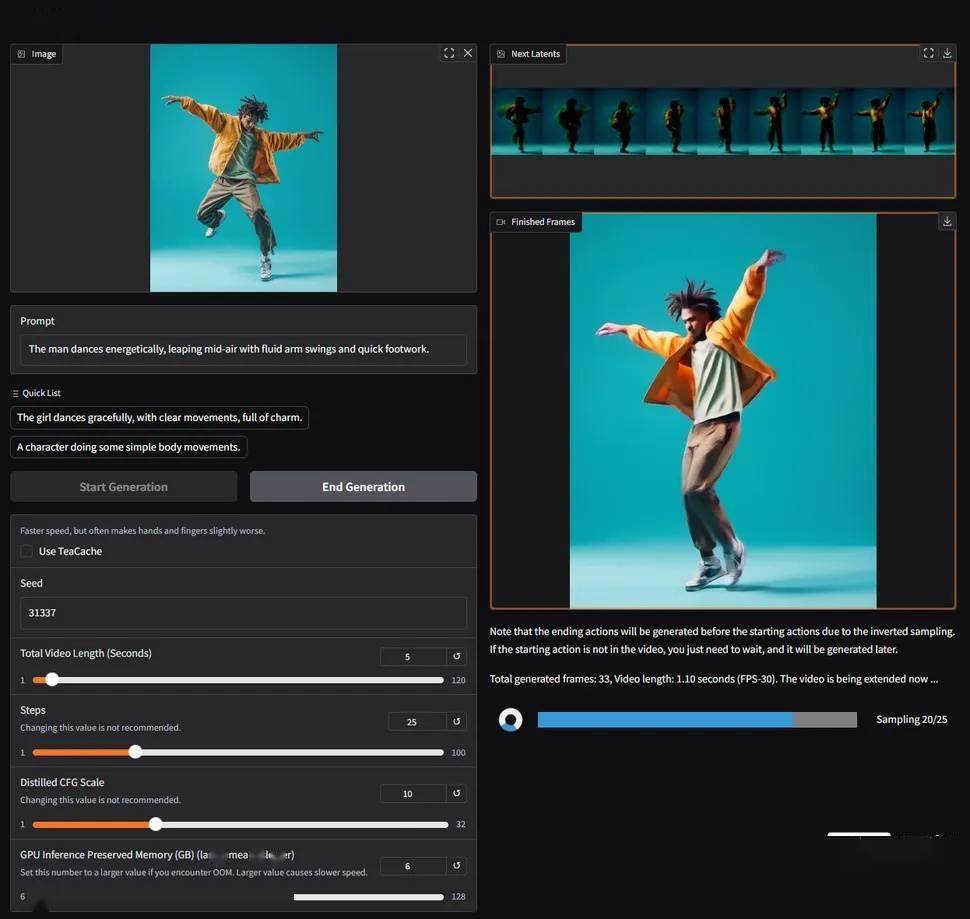
值得注意的是,framePack所使用的模型目前可能有30幀/秒的上限,這或許會限制部分用戶的需求。然而,對于大多數普通消費者而言,framePack的出現無疑為他們進行AI視頻創作提供了極大的便利。它不僅為專業內容創作者提供了一種替代昂貴第三方云服務的可行方案,還為非專業用戶制作GIF動圖、表情包等娛樂內容提供了有趣的工具。
隨著framePack技術的不斷發展和完善,相信未來會有更多的用戶能夠享受到AI視頻生成帶來的樂趣和便利。這一技術的出現,無疑為AI視頻生成領域注入了新的活力和希望。