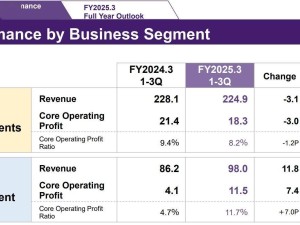
近期,AI技術領域迎來重大進展,DeepSeek V3與R1系列開源AI大模型在多語言處理與復雜邏輯推理任務中展現出了非凡實力。這一成就不僅加速了AI技術的普及,更為開源社區注入了新的活力。
眾多科技巨頭迅速響應,紛紛開始支持并部署DeepSeek模型,同時,國產硬件廠商也加快了兼容步伐。作為國內領先的全功能GPU創新企業,摩爾線程在第一時間成功實現了對DeepSeek蒸餾模型推理服務的高效部署,為開發者提供了一個基于其全功能GPU進行AI應用創新的全新平臺。
為了讓更多用戶能夠親身體驗這一創新技術,摩爾線程提供了一個便捷的在線體驗地址。用戶還可以利用摩爾線程的MTT S80與MTT S4000顯卡,輕松實現DeepSeek-R1蒸餾模型的推理部署。
早在春節前,已有B站UP主在摩爾線程的MTT S80顯卡上完成了相關實踐,并分享了寶貴的經驗。
(視頻鏈接)
DeepSeek提供的蒸餾模型技術,使得大規模模型的能力得以遷移至更小、效率更高的版本,從而在國產GPU上實現高性能推理。摩爾線程憑借其自研的全功能GPU,通過結合開源與自研的雙引擎方案,迅速完成了對DeepSeek蒸餾模型的推理服務部署。
在開源框架適配方面,摩爾線程基于Ollama開源框架,成功部署了DeepSeek-R1-Distill-Qwen-7B蒸餾模型,并在多種中文任務中展現出了卓越性能,這充分驗證了摩爾線程自研全功能GPU的通用性和CUDA兼容性。
而在自研引擎加速方面,摩爾線程通過自主研發的高性能推理引擎,結合軟硬件協同優化技術,通過定制化的算子加速和內存管理,顯著提升了模型的計算效率和資源利用率。這一引擎不僅為DeepSeek蒸餾模型的高效運行提供了有力支持,更為未來更多大規模模型的部署奠定了堅實基礎。
摩爾線程即將推出其自主設計的夸娥(KUAE)GPU智算集群,該集群將全面支持DeepSeek V3、R1模型以及新一代蒸餾模型的分布式部署。夸娥集群集成了先進的推理技術與分布式計算框架,將確保大規模模型的高效穩定運行,從而助力開發者快速實現業務落地。