在科技界的萬眾矚目下,DeepSeek開源周的精彩繼續上演,此次推出的高性能矩陣計算庫DeepGEMM,無疑成為了眾人矚目的焦點。這款被譽為“AI數學加速器”的開源工具,旨在為大模型訓練和推理提供前所未有的速度提升。
DeepGEMM在Hopper架構的GPU上實現了驚人的FP8精度下1350+ TFLOPS的算力表現。這一數字遠超當前市面上的主流顯卡,如RTX 4090的400-500 TFLOPS,展現了其卓越的性能優勢。FP8精度,即8位浮點數格式,通過犧牲微小的精度換取了3倍以上的速度提升,這一策略在AI場景中尤為適用,因為AI應用通常對誤差具有一定的容忍性。
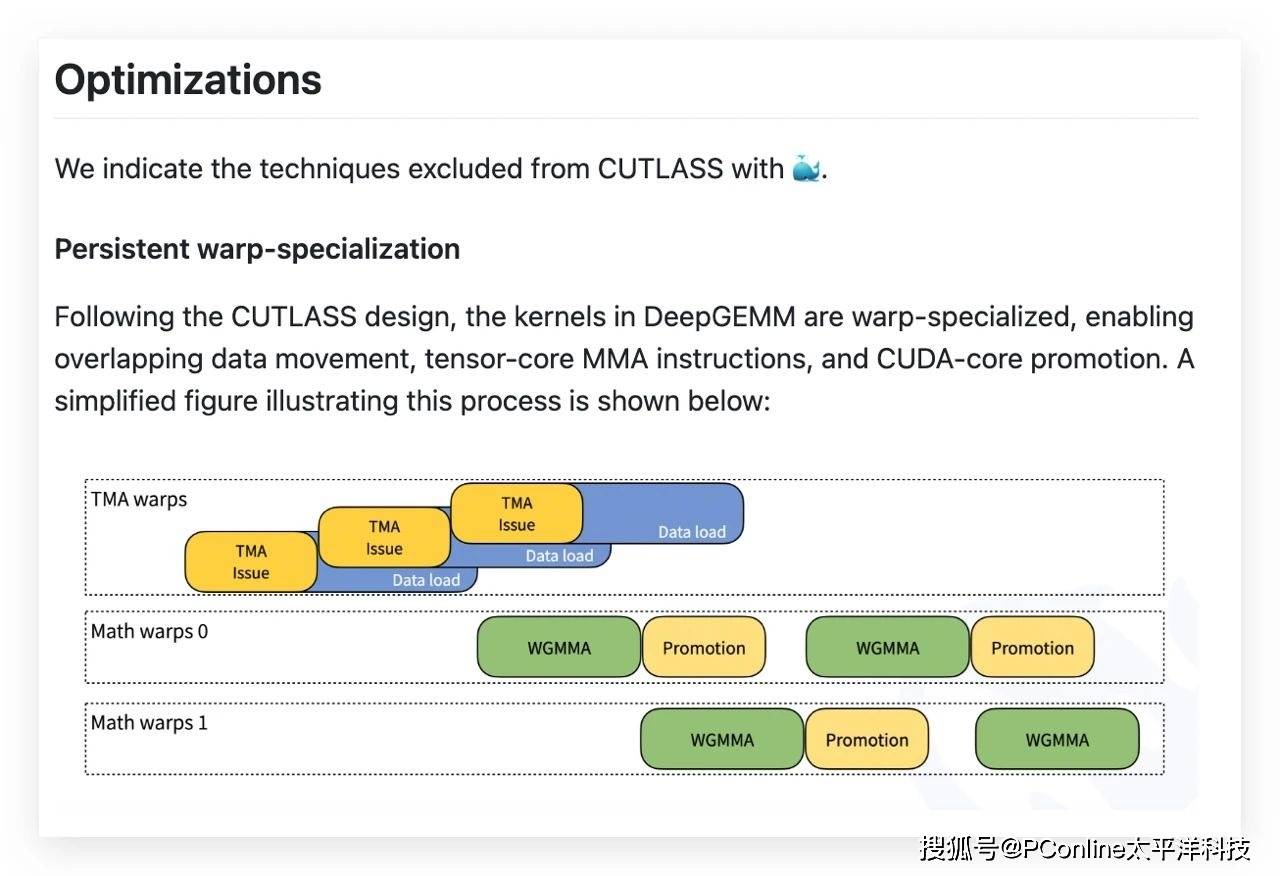
更令人驚嘆的是,DeepGEMM的核心邏輯僅用300行代碼實現,卻通過全流程JIT編譯優化,達到了比手工調優算子更高的效能。這一極簡代碼哲學,不僅摒棄了冗余設計,還專注于底層優化,重新定義了高性能計算的邊界。開發者可以輕松地將DeepGEMM集成到現有框架中,無需額外的依賴項。
DeepGEMM還支持雙模式,即稠密矩陣布局和混合MoE布局,以適應不同模型的需求。稠密矩陣布局適用于全量數據的統一計算,而混合MoE布局則能夠分任務處理,提高了計算的靈活性。

在FP8精度下,DeepGEMM還展現出了“省電模式”的優勢。低精度計算大幅降低了顯存占用和功耗,使得萬億參數的大模型在24G顯存的單卡上也能實現28倍的推理加速。這一特性在KTransformers項目中得到了驗證。
DeepGEMM在MoE模型上進行了殺手級優化。通過連續/掩碼雙布局,解決了專家模型計算中的通信瓶頸,使得萬億參數的MoE推理速度如閃電般迅速。這一優化不僅提升了性能,還進一步降低了計算成本。
DeepGEMM的開源,預示著DeepSeek在算力領域的又一次重大突破。據悉,DeepSeek正在加速推出其R1模型的升級版——DeepSeek R2,預計將在5月發布。這一升級版將借助DeepGEMM的強大算力,進一步提升模型訓練和推理的速度。

與此同時,DeepSeek也重新開放了API充值入口。此前,由于資源緊張,該入口一度關閉。目前,deepseek-chat模型的優惠期已經結束,調用價格已調整為每百萬輸入tokens 2元,每百萬輸出tokens 8元。這一調整旨在更好地滿足用戶的需求,同時也為DeepSeek的持續發展提供了資金支持。




















