小米大模型團隊近日宣布,在音頻推理技術方面取得了顯著進步。該團隊受DeepSeek-R1項目的啟發,成功將強化學習算法應用于多模態音頻理解任務,這一創新實踐僅耗時一周,便在國際權威的MMAU音頻理解評測中取得了64.5%的準確率,成功登頂榜首,并且已經同步開源。
據悉,DeepSeek-R1項目中提出的Group Relative Policy Optimization(GRPO)方法,使得模型能夠通過“試錯-獎勵”機制自主進化,展現出類似人類的反思和多步驗證等高級推理能力。小米團隊受此啟發,嘗試將GRPO算法遷移到自家的Qwen2-Audio-7B模型上,取得了令人矚目的成果。
在訓練樣本方面,小米團隊僅使用了AVQA數據集中的3.8萬條樣本進行強化學習微調,便在MMAU評測集上實現了64.5%的準確率。這一成績不僅刷新了記錄,而且相比目前榜單上排名第一的商業閉源模型GPT-4o,有近10個百分點的優勢。
盡管取得了如此顯著的進步,但小米團隊表示,當前模型的準確率距離人類專家的82%水平仍有差距。他們將繼續努力,不斷優化算法和模型,以期達到更高的準確率。
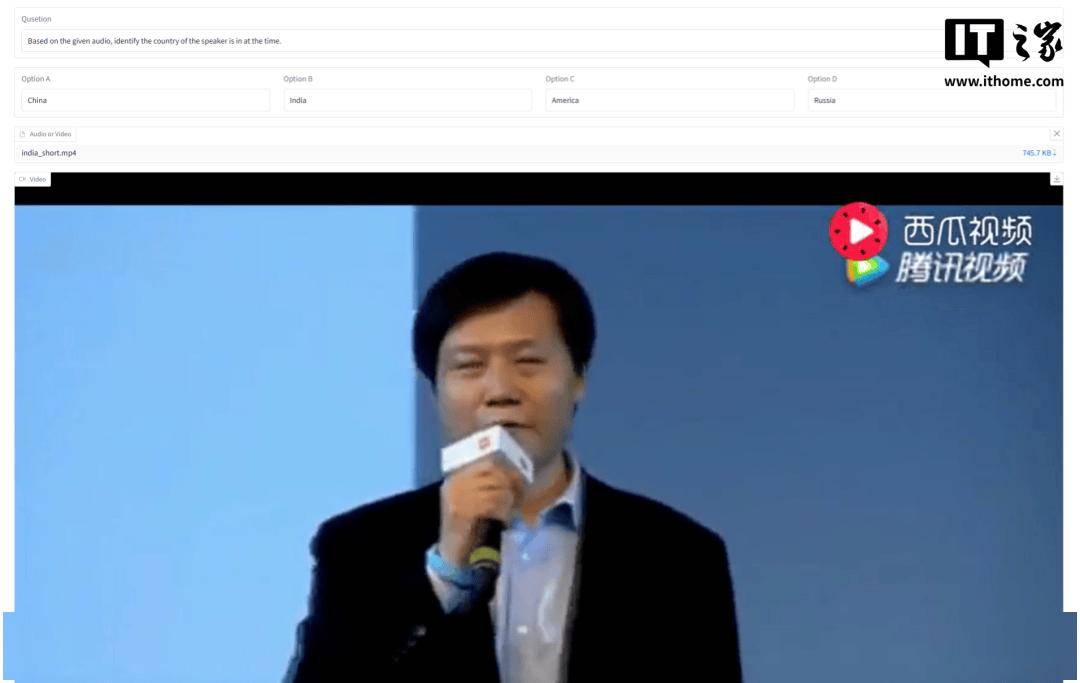
在官方提供的交互demo中,小米團隊選擇了雷軍2015年“R U OK”的視頻作為默認分析對象,展示了模型在實際應用中的表現。這一選擇不僅富有趣味性,也體現了小米團隊對于用戶需求和場景理解的深入洞察。
小米技術官微在發布這一消息時表示,音頻推理技術的突破將為智能語音助手、智能家居等領域帶來更加智能和人性化的體驗。他們期待與更多合作伙伴共同探索這一技術的廣闊應用前景。
小米團隊還強調了開源的重要性。他們認為,通過開源可以吸引更多開發者參與到技術的創新和優化中來,共同推動人工智能技術的發展和進步。