英偉達(dá)在NVIDIA GTC 2025大會(huì)上宣布,其最新推出的NVIDIA Blackwell DGX系統(tǒng)在DeepSeek-R1大模型推理性能上創(chuàng)造了世界紀(jì)錄。這一突破性進(jìn)展標(biāo)志著英偉達(dá)在人工智能推理技術(shù)上的又一次飛躍。
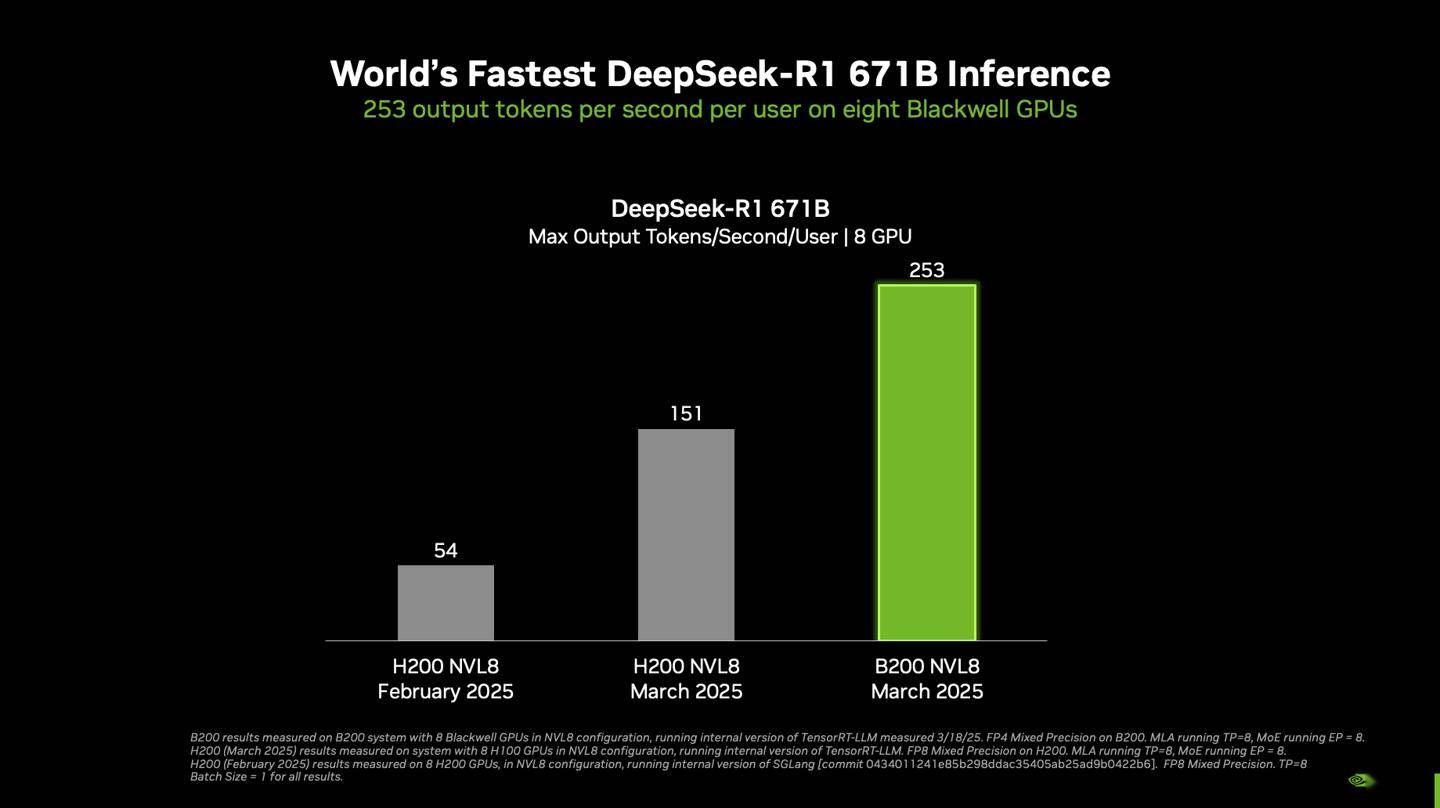
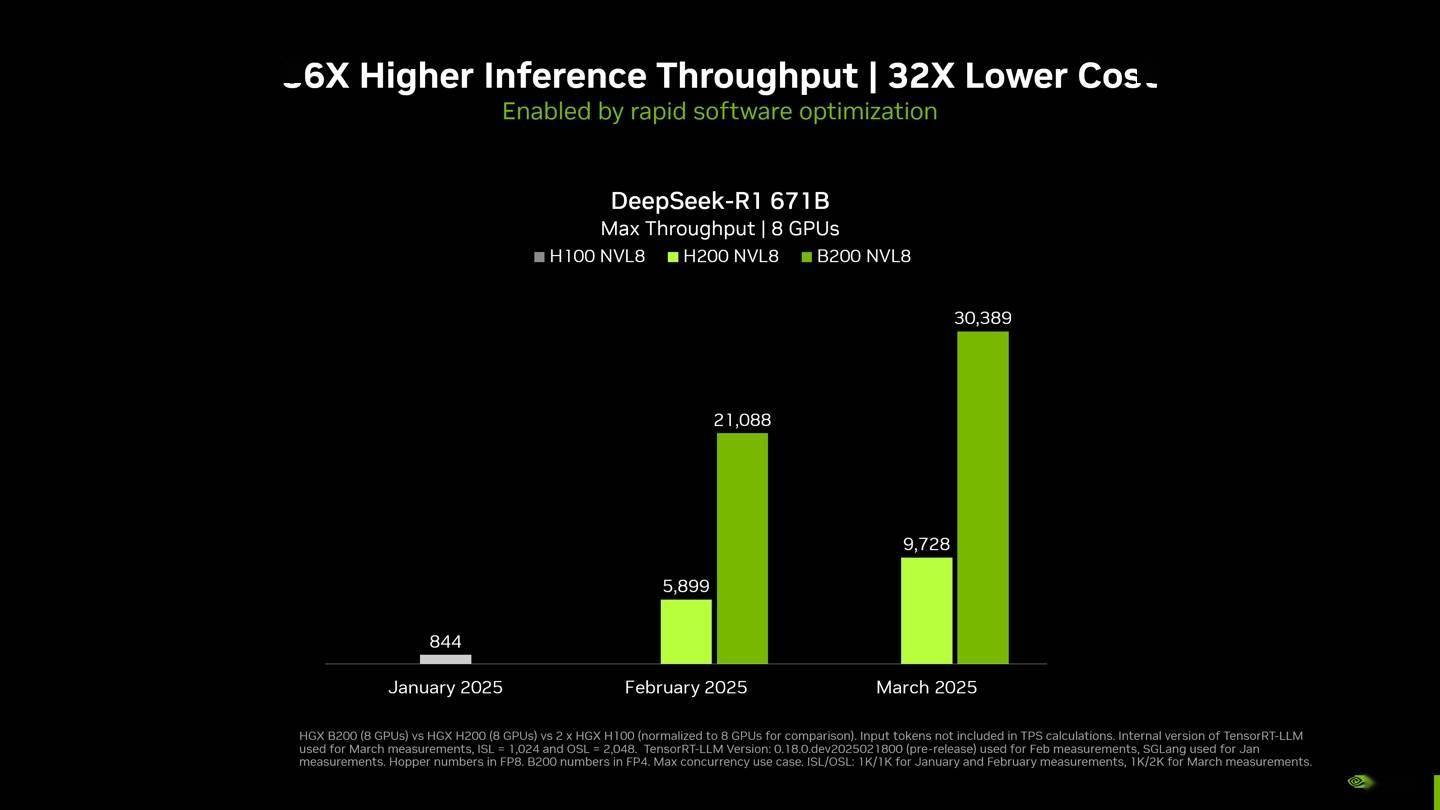
據(jù)悉,在單個(gè)搭載八塊Blackwell GPU的DGX系統(tǒng)上,DeepSeek-R1模型以6710億參數(shù)的滿血狀態(tài)運(yùn)行,實(shí)現(xiàn)了每用戶每秒超過250 token的響應(yīng)速度,系統(tǒng)整體吞吐量更是突破了每秒3萬token的大關(guān)。這一數(shù)據(jù)不僅彰顯了Blackwell GPU的強(qiáng)大性能,也展示了英偉達(dá)在優(yōu)化大型語言模型推理方面的深厚實(shí)力。

英偉達(dá)強(qiáng)調(diào),隨著Blackwell Ultra GPU和Blackwell GPU的不斷升級(jí),NVIDIA平臺(tái)將繼續(xù)在推理性能上實(shí)現(xiàn)新的突破。這一承諾不僅體現(xiàn)在硬件上,還體現(xiàn)在軟件優(yōu)化上。英偉達(dá)通過結(jié)合硬件和軟件的力量,自2025年1月以來,成功將DeepSeek-R1 671B模型的吞吐量提高了約36倍。
在會(huì)上,英偉達(dá)還展示了不同配置下的DGX系統(tǒng)性能。包括DGX B200(8塊GPU)和DGX H200(8塊GPU)在內(nèi)的單節(jié)點(diǎn)配置,在采用TensorRT-LLM軟件的最新內(nèi)部版本進(jìn)行測試時(shí),展現(xiàn)了出色的推理性能。測試參數(shù)包括輸入1024 token和輸出2048 token,并發(fā)性達(dá)到最大。在計(jì)算精度上,B200采用了FP4精度,而H200則采用了FP8精度。
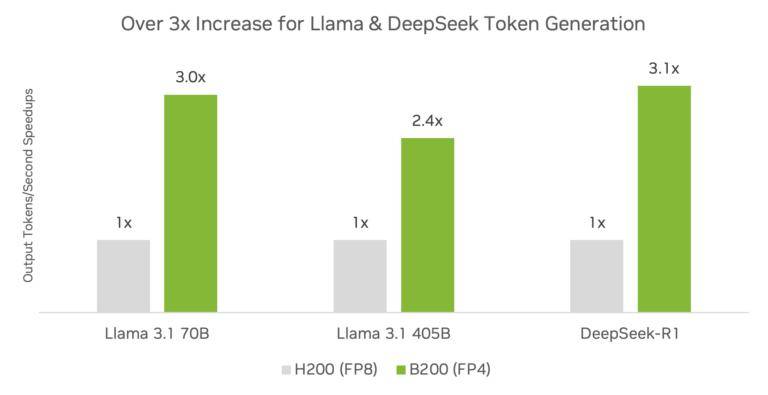
英偉達(dá)還對(duì)比了Blackwell架構(gòu)與Hopper架構(gòu)在推理性能上的差異。結(jié)果顯示,Blackwell架構(gòu)與TensorRT軟件相結(jié)合,可以顯著提升推理性能。在DeepSeek-R1、Llama 3.1 405B和Llama 3.3 70B等模型上,使用FP4精度的DGX B200平臺(tái)和DGX H200平臺(tái)相比,推理吞吐量提高了3倍以上。
英偉達(dá)還展示了不同數(shù)據(jù)集上DeepSeek-R1模型的精度表現(xiàn)。在FP4和FP8精度下,DeepSeek-R1模型在MMLUG、SM8K、AIME 2024、GPQA和DiamondMATH-500等數(shù)據(jù)集上的表現(xiàn)均十分出色。值得注意的是,在使用TensorRT Model Optimizer的FP4訓(xùn)練后量化(PTQ)技術(shù)時(shí),DeepSeek-R1模型在不同數(shù)據(jù)集上的精度損失微乎其微,這進(jìn)一步證明了英偉達(dá)在量化技術(shù)上的領(lǐng)先地位。
英偉達(dá)表示,在對(duì)模型進(jìn)行量化以利用低精度計(jì)算優(yōu)勢時(shí),確保精度損失最小化是生產(chǎn)部署的關(guān)鍵。通過不斷的技術(shù)創(chuàng)新和優(yōu)化,英偉達(dá)將繼續(xù)為客戶提供更高效、更準(zhǔn)確的AI推理解決方案。