OpenAI近期宣布在語音識別技術領域取得了重大進展,推出了一系列創新的語音模型,分別是gpt-4o-transcribe、gpt-4o-mini-transcribe以及gpt-4o-mini-tts。這些模型在性能上的提升,標志著語音識別和處理領域的一次重要飛躍。
其中,gpt-4o-mini模型以其超高的性價比吸引了廣泛關注。與GPT-4o相比,gpt-4o-mini的成本降低了96%至97%,相較于GPT-3.5 Turbo也便宜了60%至70%。其API定價為每百萬Tokens輸入15美分,每百萬Tokens輸出60美分,為開發者提供了更為經濟且高效的解決方案。
GPT-4o模型的一大亮點在于其多語言處理能力,能夠支持50種不同語言的語音識別,極大地拓寬了其應用場景。該模型在響應速度和質量上也實現了顯著提升,能夠在極短的時間內——最短僅232毫秒——對音頻輸入做出反應,這一速度已接近人類的對話反應時間。更令人驚喜的是,GPT-4o還具備情緒識別能力,使得人機交互變得更加自然流暢。
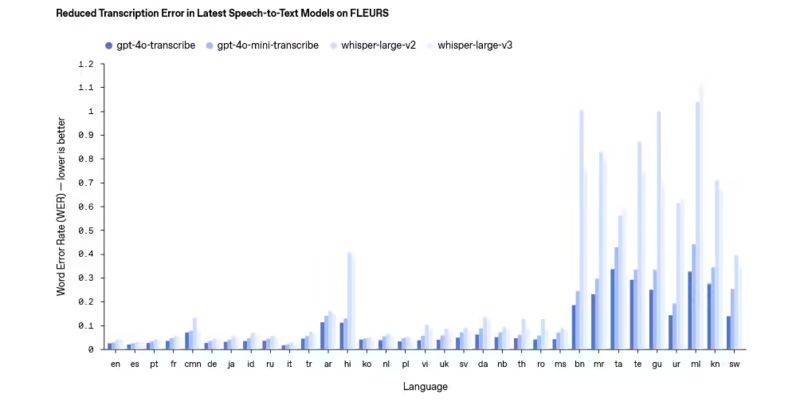
在語音轉文本(STT)方面,新推出的模型同樣表現出色。特別是在口音適應、嘈雜環境處理以及不同語速識別等方面,這些模型展現出了優于現有解決方案的性能。這一特點使得它們在呼叫中心、會議記錄等實際應用場景中更具優勢。同時,文本轉語音(TTS)模型也為開發者提供了更多自定義選項,如設定不同的語音風格,從而為用戶提供更具表現力和溫度的語音體驗。
據OpenAI介紹,這些創新模型的推出,不僅將極大地推動語音識別技術的發展,還將為各行各業帶來更加智能化、高效化的解決方案。開發者們可以借此機會,開發出更加符合用戶需求、更加智能的應用產品,為用戶帶來更加便捷、高效的使用體驗。