近日,微軟在Hugging Face平臺上推出了一款名為Phi-4的小型語言模型,并于2025年初正式向公眾開放下載和使用。這款模型雖然參數量僅為140億,但在多項基準測試中卻展現出了非凡的性能。
Phi-4自2024年12月12日首次亮相以來,便引起了開發者和愛好者的廣泛關注。2025年1月8日,微軟正式將其面向公眾開放,允許用戶進行下載、微調和部署。這一舉措無疑為自然語言處理領域注入了新的活力。
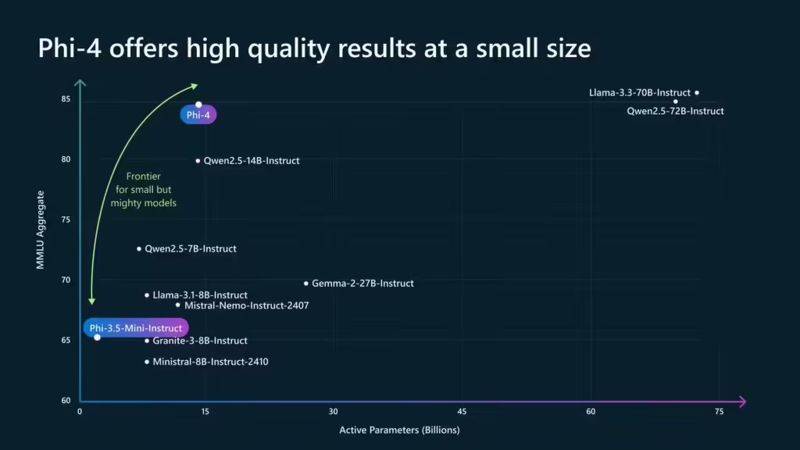
令人驚訝的是,Phi-4在性能上甚至超越了某些參數量更大的模型。例如,在與Llama 3.3 70B和OpenAI的GPT-4o Mini的對比測試中,Phi-4展現出了更為出色的表現。這一結果無疑證明了微軟在模型訓練和數據集選擇方面的深厚實力。
特別是在數學競賽問題方面,Phi-4更是展現出了其卓越的問題解決能力。據測試,其表現已經超越了Gemini 1.5 Pro和OpenAI的GPT-4o,成為了這一領域的佼佼者。這一成就不僅體現了Phi-4在復雜問題處理方面的優勢,也為其在教育和科研領域的應用提供了廣闊的前景。
微軟方面表示,Phi-4之所以能夠在性能上取得如此突出的表現,主要得益于其選擇了高質量的數據集進行訓練。這一策略不僅提升了模型的準確性,還使其能夠更好地理解和處理各種復雜的自然語言任務。然而,目前Phi-4尚未針對推理進行優化,這意味著其在實際應用中的性能可能還有一定的提升空間。
盡管如此,Phi-4的推出仍然為自然語言處理領域帶來了新的希望和機遇。未來,隨著開發者對其進行進一步的優化和量化,相信這款模型將能夠在個人電腦等設備上實現本地運行,從而進一步提高其實用性和普及率。這將為自然語言處理技術的發展和應用帶來更加廣泛的影響和推動。



















