摩爾線程今日宣布了一項重大開源舉措,正式推出了MT-MegatronLM與MT-TransformerEngine兩大AI框架。這一舉措標志著摩爾線程在國產全功能GPU上實現了混合并行訓練和推理的重大突破。
據摩爾線程官方介紹,MT-MegatronLM是一個專為全功能GPU設計的開源混合并行訓練框架。它不僅能夠支持dense模型和多模態模型的高效訓練,還特別擅長處理MoE(混合專家)模型。而MT-TransformerEngine則專注于Transformer模型的訓練與推理優化,通過一系列技術革新,如算子融合和并行加速策略,充分挖掘了摩爾線程全功能GPU的計算潛力。
兩大框架的技術亮點在于硬件適配與算法創新的深度融合。其中,混合并行訓練技術能夠靈活應對不同模型架構的復雜運算場景,而FP8混合訓練策略則結合摩爾線程GPU原生支持的FP8混合精度訓練,有效提升了訓練效率。高性能算子庫muDNN與通信庫MCCL的深度集成,進一步優化了計算密集型任務和多卡協同的通信開銷。
在實際應用方面,摩爾線程展示了令人矚目的成果。在全功能GPU集群上,Llama3 8B模型的訓練任務在FP8混合精度加速技術的加持下,實現了28%的加速,且loss幾乎無損。同時,摩爾線程還成功復現了DeepSeek滿血版訓練流程,展示了其對復雜AI訓練任務的高效支持。

兩大框架還具備完善的異常處理和兼容性。內置的rewind異常恢復機制能夠自動回滾至最近穩定節點繼續訓練,確保了大規模訓練的穩定性。同時,兩大框架兼容GPU主流生態,為開發者構建自有的AI技術棧提供了底層支撐。
摩爾線程官方表示,他們將持續優化MT-MegatronLM與MT-TransformerEngine框架,并引入更多先進功能。未來,用戶將能夠體驗到Dual Pipe / ZeroBubble并行策略帶來的更高并行訓練效率,以及多種FP8優化策略帶來的性能和穩定性提升。異步checkpoint策略和優化后的重計算策略也將進一步提高訓練過程中的容錯能力和效率。
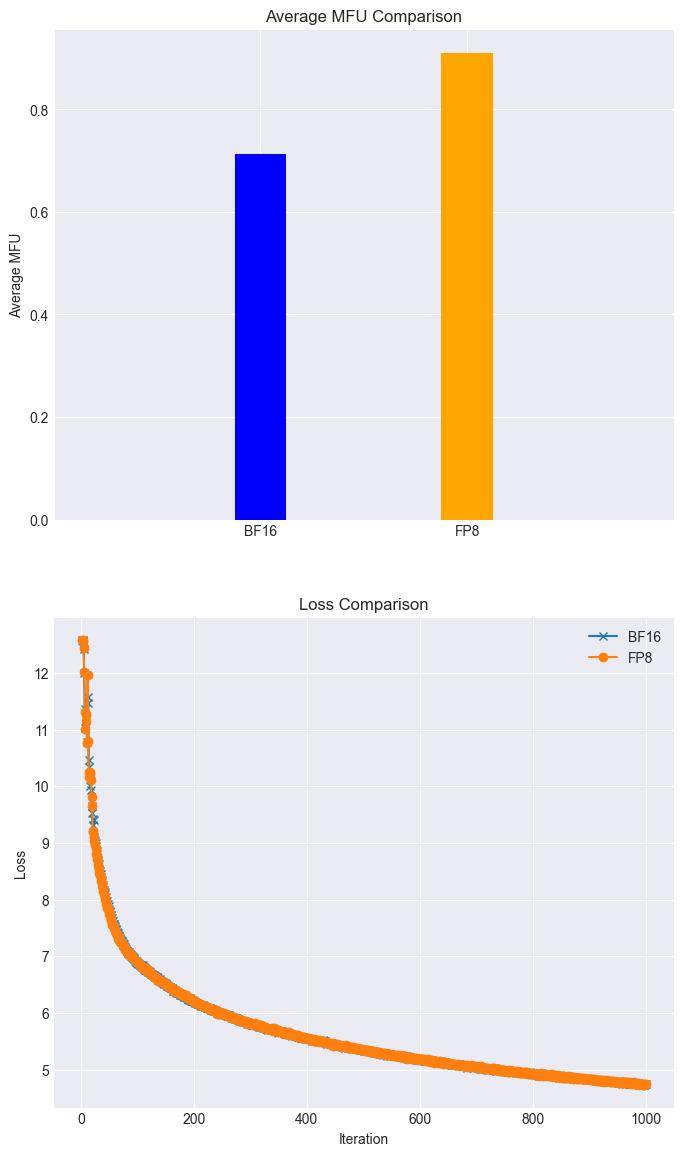
摩爾線程的這一開源舉措無疑為AI領域注入了新的活力。通過開放兩大核心框架,摩爾線程不僅展示了其在國產GPU技術上的深厚積累,也為廣大開發者提供了一個強大的AI開發平臺。未來,隨著框架的不斷優化和功能的持續引入,我們有理由相信,摩爾線程將在AI領域取得更加輝煌的成就。
對于感興趣的開發者和研究人員,可以通過以下鏈接獲取兩大框架的開源代碼:
MT-MegatronLM開源地址:https://github.com/MooreThreads/MT-MegatronLM
MT-TransformerEngine開源地址:https://github.com/MooreThreads/MT-TransformerEngine
摩爾線程Simumax開源地址:https://github.com/MooreThreads/SimuMax