近期,由知名人工智能專家弗朗索瓦·肖萊攜手創立的非營利組織Arc Prize基金會,在其官方博客上揭曉了一項名為ARC-AGI-2的全新測試。該測試旨在深入評估當前領先的人工智能模型的通用智能水平,其難度系數極高,令眾多AI模型望塵莫及。
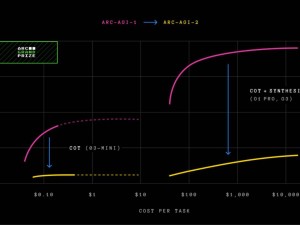
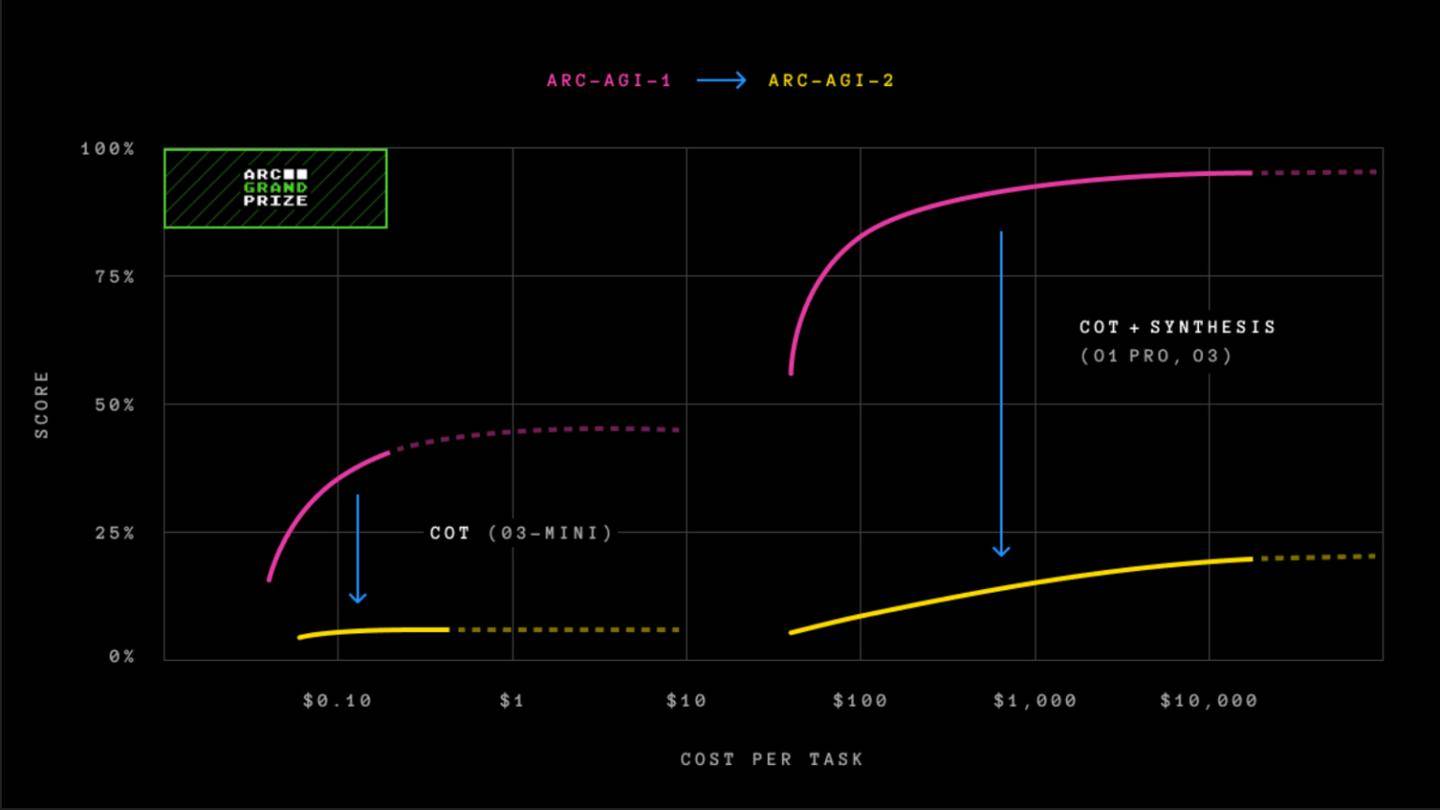
根據Arc Prize排行榜的數據揭示,那些在推理領域表現突出的AI模型,例如OpenAI的o1-pro和DeepSeek的R1,在ARC-AGI-2測試中的得分僅僅徘徊在1%至1.3%之間。即便是GPT-4.5、Claude 3.7 Sonnet和Gemini 2.0 Flash等強大的非推理型模型,其得分也僅維持在1%左右的低水平。
ARC-AGI測試由一系列復雜謎題構成,要求AI從一組色彩斑斕的方塊中辨識出隱藏的視覺規律,并據此生成正確的“答案網格”。這些問題設計精巧,旨在考驗AI面對全新問題的應變能力。為了設定人類基線,Arc Prize基金會邀請了超過400名參與者參與ARC-AGI-2測試。結果顯示,這些參與者組成的“團隊”平均正確解答了測試中60%的問題,這一成績遠超所有AI模型的表現。
肖萊在X平臺上強調,相較于先前的ARC-AGI-1測試,ARC-AGI-2更能精準反映AI模型的實際智能水平。Arc Prize基金會的測試旨在評估AI系統能否在脫離訓練數據的情況下高效習得新技能。
肖萊指出,與ARC-AGI-1相比,新的測試版本有效防止了AI模型依賴“蠻力”——即龐大的計算能力——來尋找答案。他承認,這是ARC-AGI-1的一個主要弊端。為了彌補這一不足,ARC-AGI-2引入了“效率”這一新指標,并要求模型實時解讀模式,而非依賴記憶。
Arc Prize基金會聯合創始人格雷格·卡姆拉德在其博客文章中寫道:“智能不僅僅在于解決問題或獲取高分的能力,這些能力的獲取效率和部署方式同樣至關重要。我們提出的核心問題不僅限于‘AI能否習得完成任務所需的技能?’,還包括‘以何種效率和成本?’”
ARC-AGI-1在五年內無人能敵,直到2024年12月,OpenAI發布了其先進的推理模型o3,該模型超越了所有其他AI模型,并在評估中達到了人類水平的表現。然而,當時便指出,o3在ARC-AGI-1上的卓越表現是以高昂的成本為代價的。在ARC-AGI-2測試中,即便使用價值200美元的計算資源,OpenAI的o3模型(低配版)的得分也僅為4%。
ARC-AGI-2的推出恰逢其時,科技行業正迫切呼吁建立新的、尚未飽和的基準來評估AI的進展。Hugging Face聯合創始人托馬斯·沃爾夫在最近接受采訪時指出,AI行業缺乏足夠的測試來衡量通用人工智能的關鍵特質,如創造力。
Arc Prize基金會還宣布了2025年Arc Prize競賽,向開發者發起挑戰,要求在ARC-AGI-2測試中達到85%的準確率,同時每項任務的成本不超過0.42美元(約合3元人民幣)。