meta近期推出了其最新的Llama 4系列AI模型,這一系列包括了Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth三款模型。據meta透露,這些模型均經過了龐大的未標注文本、圖像和視頻數據的訓練,旨在賦予它們廣泛的視覺理解能力。
目前,meta已將Scout和Maverick兩款模型上架至Hugging Face平臺。而Behemoth模型仍在緊鑼密鼓的訓練中。Scout模型能夠在單個英偉達H100 GPU上運行,而Maverick則需要更高配置的英偉達H100 DGX AI平臺或性能相當的設備。
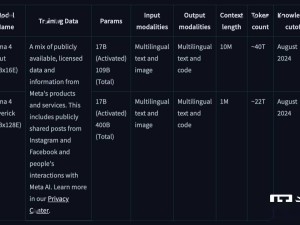
值得注意的是,Llama 4系列是meta首次采用混合專家(MoE)架構的模型。這種架構通過將數據處理任務分解為多個子任務,再將這些子任務分配給更小的、專門化的“專家”模型,從而在訓練和回答用戶查詢時展現出更高的效率。例如,Maverick模型擁有4000億個參數,但在128個“專家”模型中,只有170億個參數處于活躍狀態。
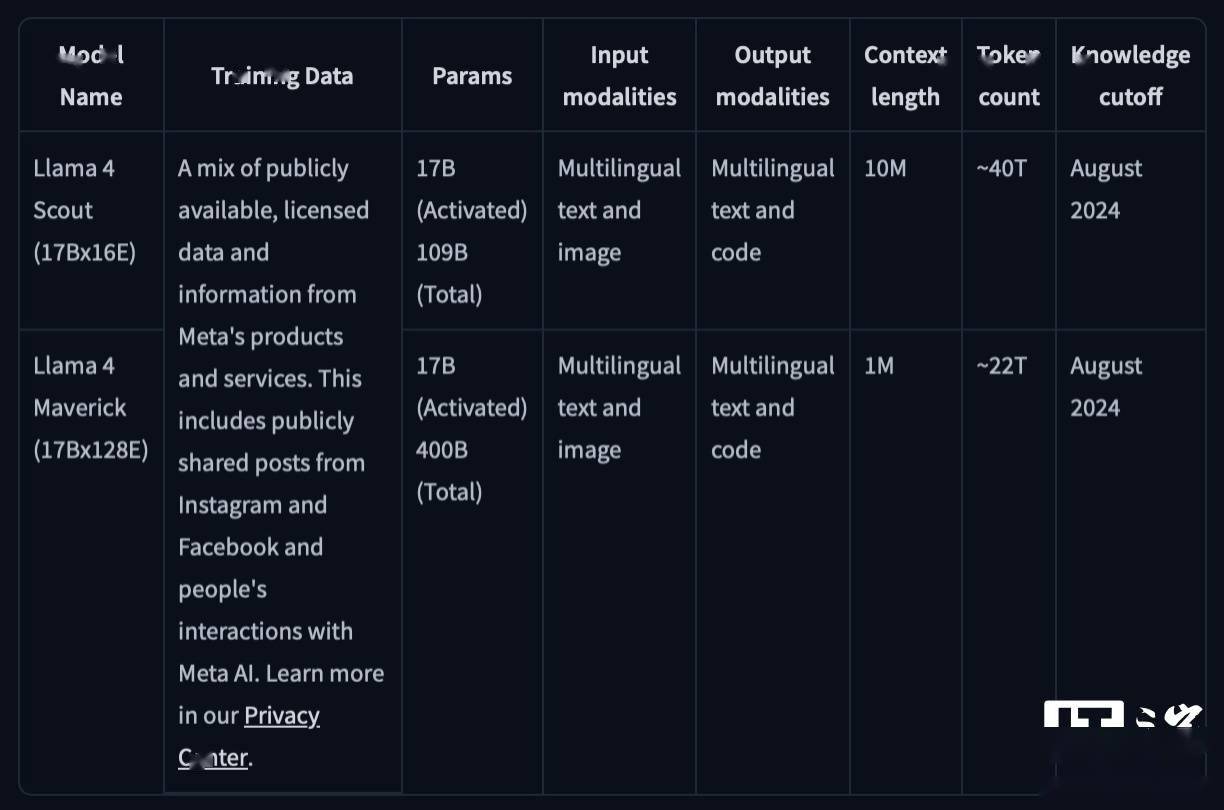
相比之下,Scout模型擁有170億個活躍參數,分布在16個“專家”模型中,總參數數為1090億個。盡管Llama 4系列模型在性能上有所提升,但它們并非像OpenAI的o1和o3-mini那樣的“推理模型”。推理模型會對答案進行事實核查,通常能更可靠地回答問題,但響應時間相對較長。
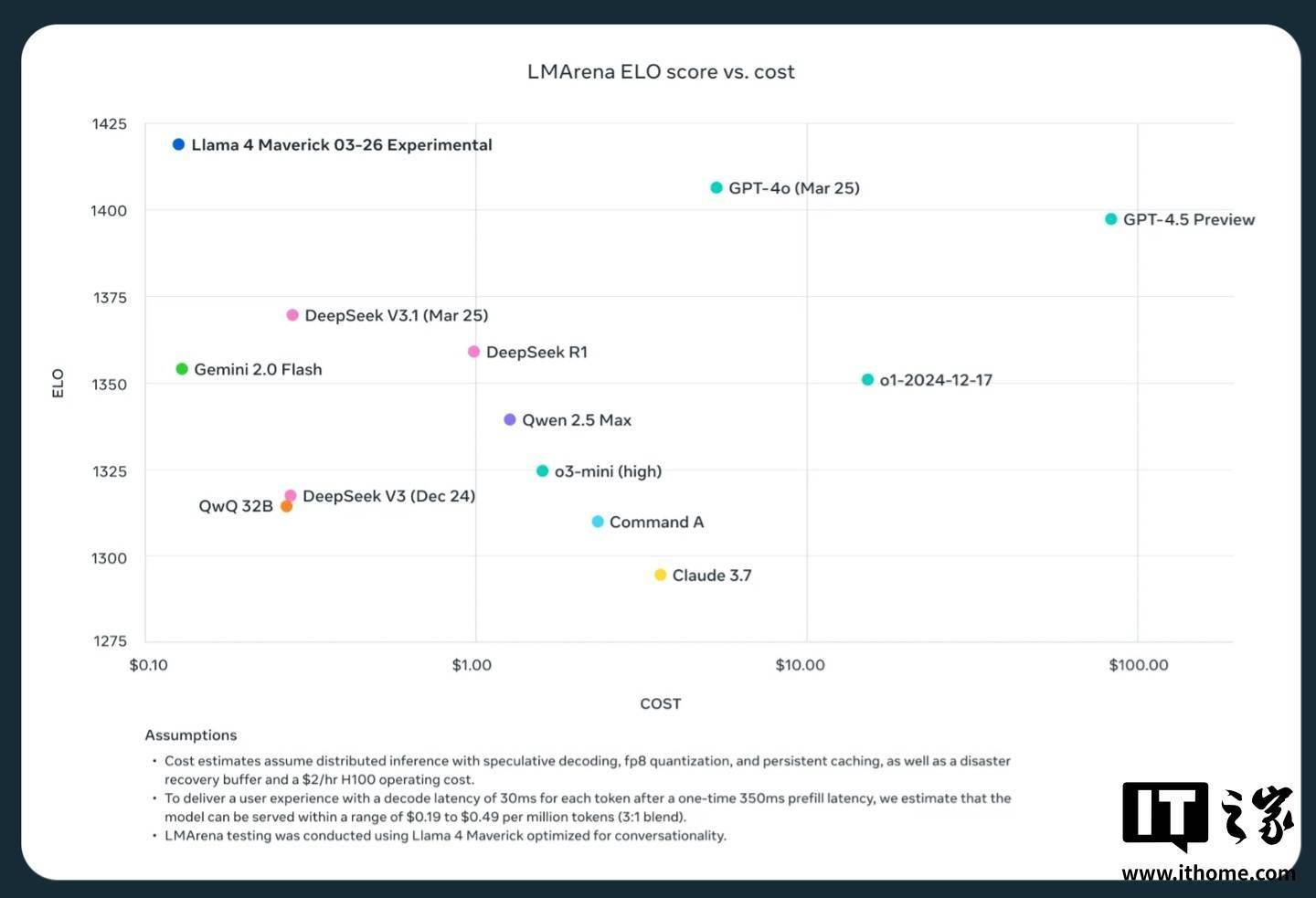
meta內部測試顯示,Maverick模型在通用AI助手和聊天等應用場景中表現出色,尤其在創意寫作、代碼生成、翻譯、推理、長文本上下文總結和圖像基準測試等方面,其性能超過了OpenAI的GPT-4和谷歌的Gemini 2.0等模型。然而,與谷歌的Gemini 2.5 Pro、Anthropic的Claude 3.7 Sonnet和OpenAI的GPT-4.5等更強大的最新模型相比,Maverick仍有一定的提升空間。
Scout模型則擅長總結文檔和基于大型代碼庫進行推理。該模型支持處理1000萬個詞元,這意味著它一次能夠處理數百萬字的文本。meta還預告了其Behemoth模型。據透露,Behemoth擁有2880億個活躍參數,分布在16個“專家”模型中,總參數數接近2萬億個。meta內部基準測試顯示,在一些衡量解決數學問題等科學、技術、工程和數學(STEM)技能的評估中,Behemoth的表現優于GPT-4.5、Claude 3.7 Sonnet和Gemini 2.0 Pro,但略遜于Gemini 2.5 Pro。