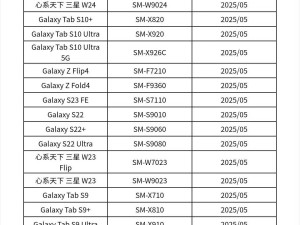
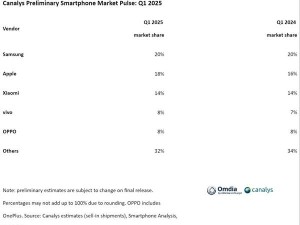
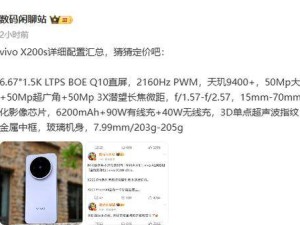
智譜科技近日正式推出了GLM-4-32B-0414系列AI模型,該系列包含GLM-4-32B-Base-0414、GLM-Z1-32B-0414、GLM-Z1-Rumination-32B-0414以及GLM-Z1-9B-0414四款各具特色的模型,均配備了高達320億的參數規模。
其中,GLM-4-32B-Base-0414模型尤為引人注目。它采用了15T的高質量數據進行預訓練,特別加入了大量推理類的合成數據,顯著提升了模型的推理能力。在后續的訓練階段,通過拒絕采樣和強化學習等先進技術的運用,該模型在指令遵循、工程代碼處理、函數調用等方面展現出了卓越的性能。在工程代碼生成、Artifacts創造、函數調用執行、搜索問答以及報告撰寫等多個應用場景中,GLM-4-32B-Base-0414的表現甚至可以與更大規模的模型相媲美。

GLM-Z1-32B-0414則是在基礎模型的基礎上,通過冷啟動技術和擴展強化學習的應用,以及在數學、代碼和邏輯等特定任務上的深入訓練,實現了數理能力和復雜任務解決能力的顯著提升。這款模型在處理涉及數學推理和復雜邏輯的問題時,展現出了更加出色的表現。
GLM-Z1-Rumination-32B-0414則是一款具備沉思能力的深度推理模型,它的設計目標是對標OpenAI的Deep Research模型。通過更長時間的深度思考和推理過程,GLM-Z1-Rumination-32B-0414能夠解決更加開放性和復雜的問題。同時,它還能夠結合搜索工具來處理各種復雜任務,進一步提升了模型的實用性和應用范圍。
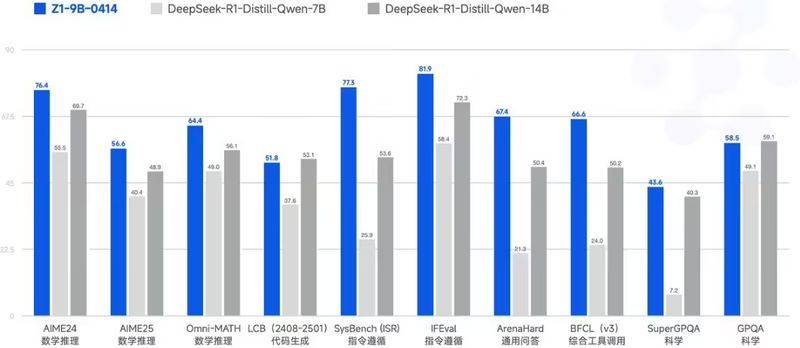
GLM-Z1-9B-0414則是一款開源的小尺寸模型,雖然參數規模相對較小,但在數學推理和通用任務中卻展現出了非凡的能力。在同尺寸的開源模型中,GLM-Z1-9B-0414的表現處于領先地位,為研究和企業提供了高性能且成本效益顯著的AI解決方案。
在各項測試中,GLM-4-32B-0414系列模型也展現出了不俗的實力。在IFeval指令遵循測試中,GLM-4-32B-0414得分高達87.6;在TAU-Bench任務自動化測試中,該模型在零售場景和航空場景中分別獲得了68.7和51.2的分數;在SimpleQA搜索增強問答測試中,GLM-4-32B-0414的得分更是達到了88.1;而在SWE-bench代碼修復測試中,該模型的成功率也高達33.8%。這些優異的成績充分證明了GLM-4-32B-0414系列模型在多個應用場景中的卓越表現。
GLM-4系列模型還采用了MIT許可協議,這大大降低了模型的計算成本和使用門檻。無論是研究機構還是企業用戶,都可以更加便捷地利用這些高性能的AI模型來推動各自領域的發展和創新。